Overtone singing, a technique of Asian origin, is a special type of voice production resulting in a very pronounced, high and separate tone that can be heard over a more or less constant drone. An acoustic analysis is presented of the phenomenon and the results are described in terms of the classical theory of speech production. The overtone sound may be interpreted as the result of an interaction of closely spaced formants. For the lower overtones, these may be the first and second formant, separated from the lower harmonics by a nasal pole‐zero pair, as the result of a nasalized articulation shifting from /c/ to /a/, or, as an alternative, the second formant alone, separated from the first formant by the nasal pole‐zero pair, again as the result of a nasalized articulation around /c/. For overtones with a frequency higher than 800 Hz, the overtone sound can be explained as a combination of the second and third formant as the result of a careful, retroflex, and rounded articulation from /c/, via schwa /E/ to /y/ and /i/ for the highest overtones. The results indicate a firm and relatively long closure of the glottis during overtone phonation. The corresponding short open duration of the glottis introduces a glottal formant that may enhance the amplitude of the intended overtone. Perception experiments showed that listeners categorized the overtone sounds differently from normally sung vowels, which possibly has its basis in an independent perception of the small bandwidth of the resonance underlying the overtone. Their verbal judgments were in agreement with the presented phonetic‐acoustic explanation.
Electroglottogram recordings during overtone singing
Gerrit Bloothooft, Guus de Krom, Susan Jansen, Allard van der Heijden
Research Institute for Language and Speech (OTS) Utrecht University Trans 10, 3512 JK Utrecht, The Netherlands
ABSTRACT
Overtone singing involves careful articulation, resulting in a closely spaced formant pair (F1/F2 or F2/F3) that enhances the amplitude of the intended overtone considerably. Apart from this articulatory explanation it is likely that the glottal sound source plays an important role during overtone singing, but this has never been explicitly investigated so far. To this end we have made electroglottograms (EGG) from an experienced singer from the Tuva Republic and from a Dutch teacher of overtone singing. Khargira and sygyt techniques and some variants were recorded, for the authentic singer during songs, and for the Dutch singer as systematic scales of overtones. Whereas normally sung vowels showed standard shapes of the EGG, the shape of the EGG deviated considerably during overtone singing, for both singers. Instead of a single full wave per period, the EGG showed modulations during a period with higher frequency components. We will present an analysis of these modulations in relation to the frequency of the amplified overtone. A comparison is made between the two singers and the different and comparable overtone singing techniques they recognized.
Contact:
Dr Gerrit Bloothooft Research Institute for Language and Speech (OTS) Utrecht University Trans 10, 3512 JK Utrecht, The Netherlands Phone: +31.30.536042 Fax: +31.30.536000 Email: bloothooft@let.ruu.nl
This is a demonstration of overtone singing. Overtone singing is an articulatory technique in which a certain overtone is amplified. You will hear a whistle over the drone of the fundamental and lower harmonics. The first fragment demonstrates a technique which is especially used in the Western countries. The tongue is very slowly moved from the position of the vowel /O/ to the position of the vowel /i:/, resulting in a special scale of overtones. The fundamental remains the same in all cases! The careful somewhat retroflex articulation brings the second and third formant together, which amplifies the nearby overtone. The overtones 5-16 can be heard. To produce the overtones 3-5, one has to make a nasal sound and articulate from /o:/ to /a:/. The overtone is then amplified by the first formant, while the nasal anti-resonance creates the acoustic distinction between the amplified overtone and the lowest harmonics. In the subsequent demonstrations, we hear song fragments containing overtone singing, from the Tuva Republic in Mongolia. The technique is not essentially different from the Western technique, but glottal adducation is much higher (almost pressed singing). The Tuva people know a number of techniques, which are related to the fundamental frequency. In these fragments you will hear Sygyt which is typically produced with a pitch of 150-200 Hz. An other technique is Kargyra, with a characteristic low pitch of less than 60 Hz. More information: Bloothooft, G., Bringmann, E., van Cappellen, M., van Luipen, J.M., and Thomassen, K.P. (1992). Acoustics and perception of overtone singing, J. Acoust. Soc. Am. 92, 1827-1836. Levin, Theodore C., and Edgerton, Michael E. (1999). The Throat Singers of Tuva, Scientific American, Sept.1999. www.harmonx.com [19 Jul 2001] with sound clips!
listen to demonstration technical details text/transcript
overtone singing Keeping a constant pitch of about 130 Hz, a professional Western performer sings a scale of the overtones 4 to 16. The narrow-band spectrogram shows the amplification of the successive overtones. The lowest overtones are amplified by the first formant, the stepwise increasing resonance is the combination of second and third formant. Higher formants are also visible.
tuva overtone singing 1 A Tuva singer demonstrates his “throat singing” or overtone singing, in which individual overtones are amplified. These overtones are clearly visible in the spectrogram.
tuva overtone singing 2 A Tuva singer demonstrates his “throat singing” or overtone singing, in which individual overtones are amplified. These overtones are clearly visible in the spectrogram.
tuva overtone singing 3 A Tuva singer demonstrates his “throat singing” or overtone singing, in which individual overtones are amplified. These overtones are clearly visible in the spectrogram.
tuva overtone singing 4 A Tuva singer demonstrates his “throat singing” or overtone singing, in which individual overtones are amplified. These overtones are clearly visible in the spectrogram.
Tuvan Overtone Singing: Harmonics Out of Place Hilary Finchum
HILARY FINCHUM-SUNG
home | staff/hours/map | publications | working papers
The region known as Tuva is contained within the southern portion of Siberia, lying in the exact geographical center of Asia. The traditional territory stretches from the Altai Mountains to the headwaters of the Yenisei, northwest of the mountain border between Russia and Mongolia. Surrounded by mountain ranges on the northeast, north, northwest, and western boundaries, Tuva was kept in relative isolation for a very long time. Economically, these people are dependent on their flocks of sheep, reindeer, horses, yaks, and others for much of the materials that are required to live in this harsh environment‹skin and fur for clothing, meat, milk, and dung for fuel.
Proximity to nature produces at once a dependency on Tuva’s resources and an intimate relationship of respect with the wonders of the natural world. This sense of intimacy is very much reflected in xcoomei, the Tuvan form of throat or overtone singing. Overtone singing is a type of singing in which one or more upper harmonics carry the melody, while the lower harmonics, including the fundamental, sustain a steady drone beneath the melody. The result is that a single singer can sing two or more pitches simultaneously.
In the recent past, some work has been done on the analysis of xoomei, and more has been done on overtone singing generally. The focus on this research has been on the effort to discover exactly how overtone melodies are produced. Hypotheses as to the mechanics of overtone singing range from ideas as to the necessary physical stance and posture used by the singer during a performance, to the actual physical formation of the mouth cavity in producing the overtones. Several previous researchers seem to agree that the production of the harmonics in throat singing is essentially the same as the production of an ordinary vowel. Leothaud says: “nous pouvons … conclure qu’il n’existe aucune difference de nature entre la prononciation des voyelles et l’emission diphonique” (we can conclude that there exists on difference in nature whatsoever between the pronunciation of vowels and overtone singing) (1989, 34). Similarly, Bloothooft, et al., report an entire investigation of overtone singing, based on the similarity of this kind of phonation to the articulation of vowel. The most persuasive of the researchers who approach overtone singing as vowel production is Mark Van Tongeren, who actually learned to produce the sounds of xoomei from Tuvan throat singers. In his lessons with the Tuvan singer Mongush Mergen, he says that in “explaining (to) me how to sing vowels he also commented on the physical aspects of singing, and said that I should not worry about the melodies as long as I sang the vowels properly” (Zanten and Roon 304). Different vowel sounds are supposed to produce varied effects. Van Tongeren implies that vowels are more important than the actual pitch of the overtones, since once the correct vowel sounds are produced the pitches will sound. “Apparently the most important thing is to produce the same vowel and the same sound quality” (Zanten and Roon 305).
Based on the results of acoustic analysis of Xoomei conducted at SAVAIL, I would like to argue that the physical act of creating overtones may originate in vowel production, but the end product (the actual overtones themselves) are far from vowel-like. It is not the case that the production of certain vowels will result in the presence of overtones that can carry a melody. Initial evidence that the overtones used to make melody are not vowel-like can be gathered from the fact that singers appear to be able to sing either vowels or overtone melodies, but not both at the same time; in other words, if overtones were simply vowels pronounced in a certain order, then singers could sing a text consisting of words whose vowels contained the necessary overtones to make the melody. Instead it appears that when throat singers want to include a text, they cannot melodicize overtones until the text is over; the text is “ordinary”, monophonic singing, with the fundamental frequency carrying the melody of the song; overtone melodies do not occur until the text is over. When the upper overtones become prominent enough to carry a melody, they cease to function as part of a vowel, which depends on the upper harmonics to contribute toward the sensation of timbre, (or vowel quality) rather than pitch. In fact, the Tuvans have a genre of Xoomei, called xorekteer, which is not overtone singing, consisting instead of text, with the fundamental as the melodic basis. Usually sung as an introduction to a xoomei piece, the xorekteer provides the text, which the xoomei lacks while it is focused on overtone singing.
This paper presents part of the results of larger study on Xoomei. I hope to show in this paper through acoustic analysis of a single example of Xoomei, typical of the genre and of overtone singing in general, that the necessary acoustic characteristics of overtones when they are produced for melodic purposes make then useless for timbral purposes; as soon as these overtones become prominent enough to be “heard out” as separate pitches, they fail to be fused into the unitary sensation of timbre, or vowel quality. The form of xoomei analyzed for this project is called Borbannadir which means “rolling” and thus imitates either the sound of running water, or horses hooves. The sound of borbannadir is much fuller than other forms of Xoomei, and the fundamental drone tends to be a little higher – in either the bass or baritone range.
For the analysis of the style of Xoomei in question, three different computer programs were employed. Oedipe-2.0 allowed a three-dimensional view of the progress of the harmonic envelop over time, and also allowed us to view each of the prominent harmonics as a function of time. Spectro-3.0 is an important tool in providing true energy-based frequency readings of prime harmonic peaks, rather than approximating a frequency based on its location within a calibrated window. SpecDraw was invaluable in allowing the filtering of individual harmonics, so that the prominent, melody-carrying overtones could be examined in isolation from the rest of the sound.
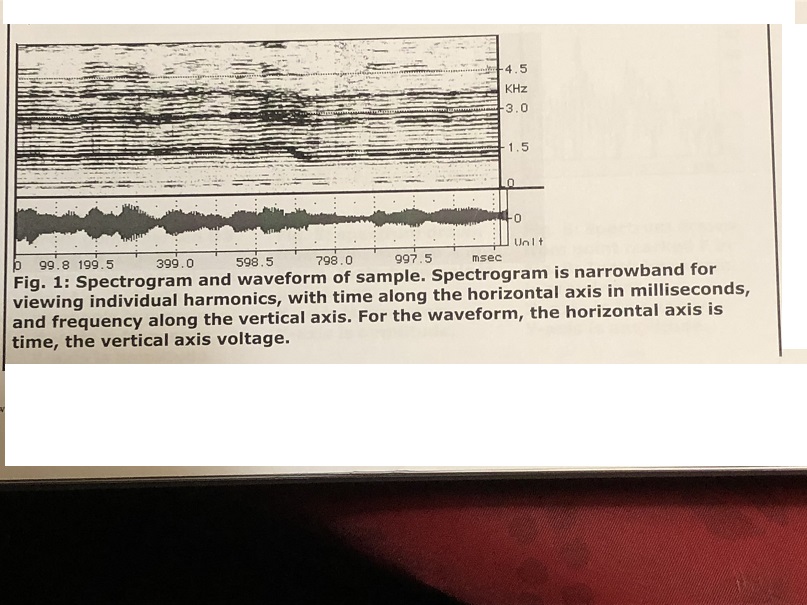
A sample of Borbannadirb is pictured below. Fig. 1 shows the entire sample as a spectrogram with its waveform; three prominent harmonics can be seen moving in parallel. Fig. 2 shows the most prominent overtoneb filtered from the remainder of the sound; the frequency scale has also been changed for closer examination. Here we see the frequency movement of the overtone, moving from 1563 Hz to 1788 Hz to 1338 Hz, which translates approximately into the sensation of the pitches G#, A, and F.
Fig. 1: Spectrogram and waveform of sample. Spectrogram is narrowband for viewing individual harmonics, with time along the horizontal axis in milliseconds, and frequency along the vertical axis. For the waveform, the horizontal axis is time, the vertical axis voltage.
Fig. 2: Spectrogram and waveform of most prominent harmonics, with frequency scale shortened for closer viewing. Spectrogram is narrowband for viewing individual harmonics, with time along the horizontal axis in milliseconds, and frequency along the vertical axis. For the wavform, the horizontal axis is time, the vertical axis voltage.
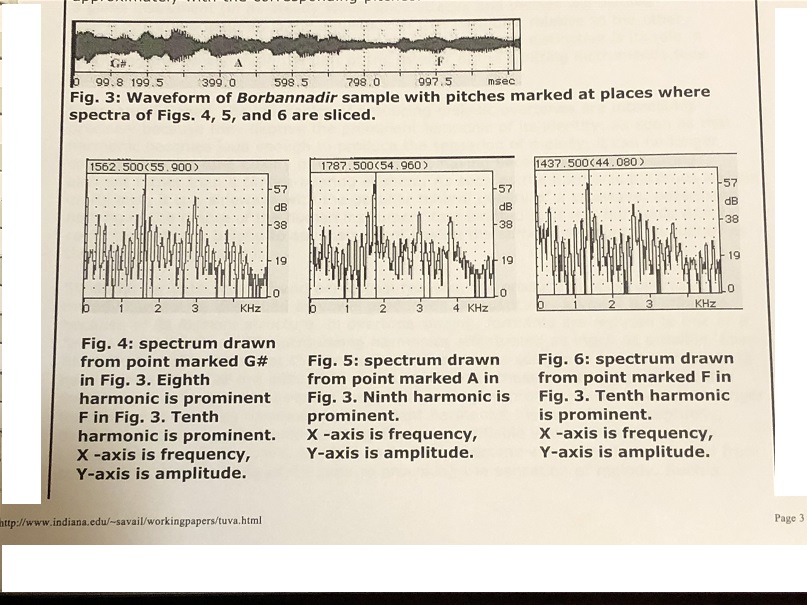
It is important to note that the overtone melody is not made from a single overtone that changes pitch over time. Rather the pitch movement of the melody in the case of the Borbannadir sample is the result of three different harmonics – the eighth, ninth, and tenth – which take their turn in prominence. This is generally true of overtone singing where the fundamental and its harmonics compose an unmoving drone with the melody above it: the melody cannot be made of a single harmonic changing frequency; instead, each pitch of the melody consists of a different harmonic, so that part of the skill of overtone singing must lie in the smooth transition from one prominent harmonic to the next. Fig. 3 shows the same waveform of the Borbannadir sample, with points marked in the middle of segment of pitch. Figs. 4, 5, and 6 show spectra of the Borbannadir sample at points coinciding exactly with the marks G#, A, and F. Each spectrum shows a different harmonic in prominence, whose frequency coincides approximately with the corresponding pitches.
Fig. 3: Waveform of Borbannadir sample with pitches marked at places where spectra of Figs. 4, 5, and 6 are sliced.
Fig. 4: spectrum drawn from point marked G# in Fig. 3. Eighth harmonic is prominent F in Fig. 3. Tenth harmonic is prominent. X -axis is frequency, Y-axis is amplitude. Fig. 5: spectrum drawn from point marked A in Fig. 3. Ninth harmonic is prominent. X -axis is frequency, Y-axis is amplitude. Fig. 6: spectrum drawn from point marked F in Fig. 3. Tenth harmonic is prominent. X -axis is frequency, Y-axis is amplitude.
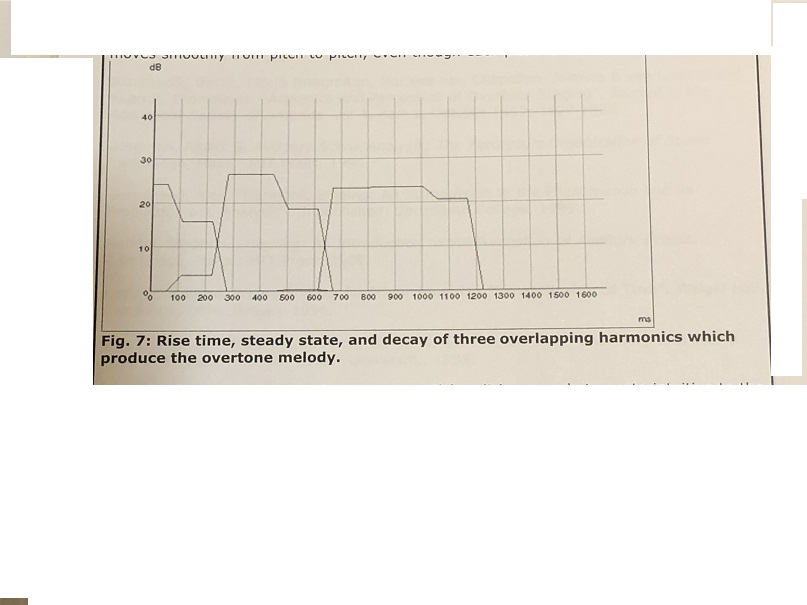
Figure 7 shows the rise time, steady state, and decay of each of the three harmonics. Notice that they overlap each other, rather than decaying sharply or leaving silence between them; this is perhaps part of the reason that the melody of the overtones moves smoothly from pitch to pitch, even though each pitch is a different harmonic.
Fig. 7: Rise time, steady state, and decay of three overlapping harmonics which produce the overtone melody.
While it will come as no surprise to an acoustician, it is somewhat counterintuitive to the musician to realize that all sounds are composed of the same physical ingredients. A harmonic of 440 Hz drawn from a violin tone will sound exactly like a harmonic of 440 Hz drawn from a flute tone, or even from a vocal tone; a single harmonic is simply a sine wave of a certain frequency, a wave of air pressure arriving to our ears from the environment, no matter what instrument emits it. What makes a harmonic distinctive to a given instrument (in its steady state, since attacks and decays will involve characteristic variations), is the amplitude of that harmonic relative to the other harmonics of the instrument. Or, what makes the harmonic distinctive is its role in producing the sensation on the part of the listener of the emitting instrument’s tone quality.
Conceptually, then, the mechanics of producing melodic overtones are interesting precisely because they deprive the prominent harmonic of its identity. As soon as that harmonic becomes loud enough to produce the sensation of melody, it can no longer contribute to the tone quality of the instrument, having become a melody-bearing element rather than a timbre-bearing element. As soon as the harmonic becomes audible on its own, it is a sinewave with the peculiar timbral quality of a sinewave, possessing nothing of the timbre of the human instrument that emitted it. It is a harmonic which could theoretically belong to any instrument having the same fundamental frequency as the tone which includes it.
Similarly, for both acoustic and perceptual reasons, the production of an overtone melody can not be described as vowel production. Acoustically, a vowel is distinctive because of its formant structure. In overtone singing, formants are reduced to one or a few harmonics, often with surrounding harmonics attentuated as much as possible. Even Bloothooft et al confess that the formants of an overtone-sung tone are so narrow as to have bandwidths that are difficult to measure. Perhaps these researchers had trouble measuring the bandwidths because the formants they wanted to measure were no longer formants, having been narrowed to prominent harmonics instead. And perceptually, overtone singing usually sounds nothing like an identifiable vowel. This is primarily because, as described above, a major part of the overtone-sung tone has switched from contributing to the timbre of the tone to provoking the sensation of melody. Such a distorted “vowel” can convey little phonetic information.
Works Cited
Bloothooft, Gerrit, Eldrid Bringmann, Marieke van Cappellen, Jolanda B van Luipen, and Koen P. Thomassen. “Acoustics and Perception of Overtone Singing”. Journal of the Acoustical Society of America. vol 4, part 1. October 1992: 1827-1836.
Bregman, Albert S. Auditory Scene Analysis: The Perceptual Organization of Sound. Cambridge, Mass.: MIT Press, 1990.
Broadhead, Alex. “Harmonic Singing: An Introduction to the Phenomenon and its Production and Analysis”. Unpublished. Dartmouth College, 1995.
Handel, Stephen. Listening: An Introduction to the Perception of Auditory Events. Cambridge, Mass.: MIT Press, 1989.
Levin, Theodore. Program notes for “Huur-Huur-Tu: Throat Singers of Tuva”. Weigel Hall. Columbus, Ohio. January 1994.
Van Zanten, William and Van Roon, Marjolijn, ed. Oideion: The Performing Arts World Wide 2. Research School: Leiden University, 1995. Publié il y a 12th January 2009 par TRAN QUANG HAI
Bloothooft, G., Bringmann, E., van Cappellen, M., van Luipen, J.M., and Thomassen, K.P. (1991). ‘A phonetic study of overtone singing’, Proc. XIIth Congress of Phonetic Sciences, Aix-en-Provence, V 14-17.
A phonetic study of overtone singing
Gerrit Bloothooft, Eldrid Bringmann, Marieke van Cappellen, Jolanda B. van Luipen, and Koen P. Thomassen
Research Institute for Language and Speech, University of Utrecht Trans 10, 3512 JK Utrecht, The Netherlands
Gerrit BLOOTHOOFT
Abstract
We describe the phenomenon of overtone singing in terms of the classical theory of speech production. The overtone sound stems from the second formant or a combination of both the second and third formants, as the result of careful, rounded articulation from //, via schwa // to /y/ and /i/. Strong nasalisation provides, at least for the lower overtones, an acoustic separation between the second and first formants, and can also reduce the amplitude of the first formant. The bandwidth of the overtone peak is remarkably small and suggests a firm and relatively long closure of the glottis during overtone phonation. Perception experiments showed that listeners categorize the overtone sounds differently from normally sung vowels.
1. Introduction
Overtone singing is a special type of voice production resulting in a very pronounced, high and separate tone which can be heard over a more or less constant base sound. The technique is rarely used in Western music but in Asia (especially Mongolia and Tibet) it is more common and overtone singing can be heard during secular and religious festivities. The high tone follows a characteristic musical scale [for instance, for pitch C3 (130.8 Hz) (- and + indicate a deviation from the exact tone): C3, C4, G4, C5, E5-, G5, A5+, C6, D6, E6-, F6+, G6, G#6+, A6+, B6-, C7,… ], from which it can be concluded that one really hears an overtone of the fundamental.
The literature contains only a few reports on overtone singing [1,5,7,8], which indicate both the importance of formants and register type. In this paper we present both an acoustic analysis of overtone singing and a study to evaluate the perception of the overtone sounds, in relation to normally sung vowels.
2. Material
We have recorded series of sung overtones from a singer with many years of experience in overtone singing, both as a performer and as a teacher. In this paper we describe the results for an Fo value of 138 Hz (C#3). In addition, 12 Dutch vowels /a/, /a/, //, /o/, /e/, //, //, /i/, /oe/, //, /u/, and /y/, sung in a normal way at the same Fo, were recorded.
3. Acoustic analysis
The recordings were digitized at a rate of 10 kHz and stored in a computer. From the middle, stable, part of each recording 300 ms was segmented. Average power spectra were obtained from FFT analyses (1024 points, shift 6.4 ms) over this segment. Formant frequencies were computed on the basis of appropriate LPC or ARMA analysis.
3.1. FFT-Spectra
Figure 1 shows the average FFT spectra of all overtone recordings. Despite the averaging procedure, the width of each individual harmonic is limited, indica-ting the stability of Fo over the interval (standard deviation of Fo was less than 0.1 semitone in all cases). It can be seen from the shifting peak in the spectra that overtone singing seems interpretable as a special use of a formant. Obviously, the singer tries to match a formant with the intended overtone frequency and succeeds very well.
Frequency (kHz)
FIG. 1. Average FFT spectra for overtone sounds, sung at Fo = 138 Hz (C#3). The overtone sounds are numbered according to the main partial involved.
3.2. Formant frequency analysis
In Fig. 2 we present formant frequency results for both the overtone sounds and the sung vowels in the F1 – F2 plane. The figure shows two modes in the production: firstly, the overtone sounds 4-6 around /u/, and secondly, the track from // to /i/.
In the first mode, it can be seen from the FFT-spectra that there is energy absorbtion around 400 Hz, indicating a strong nasalisation. The characteristic overtone sound resides in the second formant, as others [1,8] had already suggested. The bandwidth of the second formant is very narrow and, especially for the lower overtones, seldom exceeds 40 Hz. This indicates little acoustic damping in production: firm glottal closure and small losses in the vocal tract. All these characteristics indicate a low, rounded, nasalised, back vowel /u/ or // (low F1 and F2, a nasal pole/zero pair, and suppressed F3 [3]).
The second mode in the production of an overtone sound, applies for overtone frequencies higher than 800 Hz. The main peak of the spectrum still rises in tune with the intended overtone frequency and is interpreted as a combination of F2 and F3. It may be of interest that the singer explains this series of overtones with the articulatory variation during the word ‘worry’. It is known, already from the Peterson and Barney data, that in a retroflex /r/ the F3 frequency can be remarkably low and can approach the F2 frequency. This has also been mentioned by Stevens (1989), especially in combination with liprounding, while Sundberg (1987) mentioned the effect as the acoustic result of a larger cavity directly behind the front teeth.
For the higher overtone sounds, the articulation comes near /y/ and /i/, where continued lip rounding makes it possible to bring F2 and F3 together [4], although for the highest overtones a subtle lip spread may be needed to reduce the front cavity to a minimum.
FIG. 2. F1 – F2 plane for stimuli sung at Fo = 138 Hz, with positions of the vowels (IPA symbols) and overtone sounds (represented by the number of the corresponding partial).
3.3. The glottal factor
The very narrow bandwidth of the “overtone formant” suggests a good and long glottal closure. We believe that the singer used modal register, with a relatively long glottal closure, originating from a firm glottal adduction. This hypothesis does not exclude that performers may use the vocal fry register as well [7]. In all cases, the long glottal closure requires a strong adduction of the vocal folds, which could easily result in general muscular hypertension in the pharyngeal region. This may relate to the prominent role of the buccal cavity, suggested by Hai (1991).
3.4. Intensity analysis
Up to an overtone frequency of 1.5 kHz, the overtone harmonic has a stable relative intensity of -10 dB relative to overall SPL, and dominates the spectrum. For higher frequencies, the relative level of the overtone harmonic sharply drops with a slope of about -18 dB/octave.
4. The perception of overtone singing
4.1. Material, listening experiment, and analysis
As stimuli we used the combined set of 14 overtone sounds and 12 Dutch vowels. From these stimuli we used the same segment (300 ms) as had been used for the acoustical analyses, but we shaped the first and final 25 ms sinusoidally to avoid the perception of clicks. In a computer-controlled experiment, these stimuli were judged by fifteen listeners on ten 7-point bipolar semantic scales. Further details of semantic scales will be presented in a forthcoming paper. The judgements were analyzed by means of multidimensional preference analysis MDPREF [2]. In the technique of MDPREF a stimulus space is constructed in which distance corresponds to perceptual (dis)similarity.
4.2. The perceptual stimulus space
The plane of the first two dimensions of the stimulus space is shown in Fig. 3. 41 % of the total variation in the judgements was explained in this plane, while higher dimensions each explained less than 6.3 %.
FIG. 3. The perceptual stimulus space. The overtone sounds are given by the number of their corresponding partial, the vowels by their IPA symbol.
The overtone sounds and normally sung vowels are perceptually separated clusters. The vowels are situated roughly in a triangle, with the cardinal vowels /i/, /u/, and /a/ at the angles. The overtone sounds are roughly ordered according to their harmonic number, although the stimuli numbered from 4 to 10 can be described as a cluster. This probably relates to the constant relative energy of the overtone harmonic for this set. The direction of the overtone sounds is, from the lower to the higher numbers, about the same as from /u/ to /i/, as may be expected from the relation between harmonic numbers and F2 frequency values.
4.3. A physical description of the perceptual stimulus space
We attempted to match the perceptual stimulus space with multidimensional physical descriptions of the stimuli [formant frequency space (see Fig. 2), 1/3-octave bandfilter energy space both by means of the Plomp metric and the Klatt metric [2,6]]. These attempts were not successful (low correlations between coordinate values along dimensions) because of the division into two clusters of the stimulus space, for which these metrics do not present an explanation. Some additional perceptual sensitivity to the very small bandwidth of the “overtone formant”, which clearly physically separates overtone sounds and normally sung vowels, seems necessary to explain the results.
5. REFERENCES
[1]
Barnett, B.M. (1977), “Aspects of vocal multiphonics”, Interface6, 117-149.
[2]
Bloothooft, G. and Plomp, R. (1988), “The timbre of sung vowels”, JASA84, 847-860.
[3]
Fant, G. (1960), ” Acoustic theory of speech production” The Hague: Mouton.
[4]
Fujimora, O., and Lindquist, J. (1970), “Sweep-tone measurements of vocal tract characteristics”, JASA 49, 541-558.
[5]
Hai, T.Q. (1991), “New experiments about the Overtone Singing Style”, Proc. Conference ‘New ways of the voice’, Becançon, 61.
[6]
Klatt, D.H. (1982), “Prediction of perceived phonetic distance from critical-band spectra: a first step”, Proc. ICASSP, Paris, 1278-1281.
[7]
Large, J. and Murry, T. (1981), “Observations on the nature of Tibetan chant”, J. of Exp. Research in Singing 5, 22-28.
[8]
Smith, H., Stevens, K.N., and Tomlinson, R.S. (1967), “On an unusual mode of chanting by certain tibetan lamas”, JASA 41, 1262-1264.
[9]
Stevens, K.N. (1989), “On the quantal nature of speech”, J. of Phonetics 17, 3-45.
[10]
Sundberg, J. (1987), “The science of the singing voice“, Dekalb: Northern Illinois University Press.
Scientists have discovered that throat singers such as the late Kongar-ol Ondar, have differently shaped vocal cords that allow them to make the deep hum
If you try to emulate the strange low songs of throat singers from Siberia, you will probably be disappointed.
Scientists have discovered that the uniquely shaped vocal cords of people living in the Altai mountain region in southern Siberia means that only they can perform the eerie melodies composed centuries ago, which have been passed down generations.
The distinctive noise comprising a low hum with several higher notes sounded simultaneously, has featured in a song by Bjork, but hasn’t popularly spread beyond the regions because only the people of southern Siberia and Tuva can make it.
Scientists from the Institute of Philology of the Russian Academy of Sciences have discovered that native Turks have different vocal cords so only they can master the melodies, The Siberian Times reported.
Their cords are slightly wider, with a shorter voice box, allowing natives to make the unique noise, which comes deep within the throat.
Throat singers have been likened to ‘human bagpipes’ and can sing a long, low note, while making higher whistling notes and rhythm.
The study suggests that people in Europe, for example, are unable to make the noises because of their differently shaped throats.
It’s believed that Mongolian men used songs to communicate across the vast, rugged landscape.
They used natural features like mountains to ensure their voices carried long distances.
Now experts think that the way the notes were sung gradually altered the structure of people’s throats in the region.
The researchers also studied the speech of two residents in Kemerovo who speak Turkic Shor, which is spoken by around 2,800 people in south central Siberia and borrows many of its roots from Mongolian.
They used digital radiography and MRI scans to study the vocal apparatus and the brain.
The research took place in the laboratory of experimental phonetic studies, which, since its creation in the 1960s, has been used to describe the sound and features of more than 40 languages and dialects.
Mongolian throat singing is a particular variant of overtone singing practiced by people in Mongolia and Tuva.
It was added to the list of Intangible Cultural Heritage of Humanity of Unesco in 2009.
Throat singers make one or more pitches sounded simultaneously over a base note – producing a unique sound.
It is not known when the practice originated, but it thought to have passed down generations of male herders for hundreds of years. Now women are using the technique too.
The open landscape of Mongolia and southern Siberia allows the sounds to carry a great distance.
It’s thought human mimicry of nature’s sounds is also at the root of throat singing. Read more:


 shows the amplification of the successive overtones. The lowest overtones are amplified by the first formant, the stepwise increasing resonance is the combination of second and third formant. Higher formants are also visible.
shows the amplification of the successive overtones. The lowest overtones are amplified by the first formant, the stepwise increasing resonance is the combination of second and third formant. Higher formants are also visible. A Tuva singer demonstrates his “throat singing” or overtone singing, in which individual overtones are amplified. These overtones are clearly visible in the spectrogram.
A Tuva singer demonstrates his “throat singing” or overtone singing, in which individual overtones are amplified. These overtones are clearly visible in the spectrogram. A Tuva singer demonstrates his “throat singing” or overtone singing, in which individual overtones are amplified. These overtones are clearly visible in the spectrogram.
A Tuva singer demonstrates his “throat singing” or overtone singing, in which individual overtones are amplified. These overtones are clearly visible in the spectrogram. A Tuva singer demonstrates his “throat singing” or overtone singing, in which individual overtones are amplified. These overtones are clearly visible in the spectrogram.
A Tuva singer demonstrates his “throat singing” or overtone singing, in which individual overtones are amplified. These overtones are clearly visible in the spectrogram. A Tuva singer demonstrates his “throat singing” or overtone singing, in which individual overtones are amplified. These overtones are clearly visible in the spectrogram.
A Tuva singer demonstrates his “throat singing” or overtone singing, in which individual overtones are amplified. These overtones are clearly visible in the spectrogram.





 +1
+1