Asian Music, the journal of the Society for Asian Music, is the leading journal devoted to ethnomusicology in Asian music, publishing all aspects of the performing arts of Asia and their cultural context.
Paul Mayne // Western NewsWestern Science professor Natasha Mhatre was a member of an international research team that uncoupled the mystery of how Tuvan throat singers produce distinctive sounds in which you can hear two different pitches at once.
An international research team has uncoupled the mystery of how Tuvan throat singers produce distinctive sounds in which you can hear two different pitches at once – a low rumble and a high whistle-like tone.
Fascinated with how this form of throat singing, known as Khoomei, creates this dual tone, researchers from Western, York University and the University of Arizona studied members of the Tuvan performing group Huun Huur Tu to examine first-hand how they do it.
“They can produce two different pitches, which goes against the typical way we think about how speech sounds are produced,” says lead researcher Christopher Bergevin from York’s Faculty of Science. “It was a bit of a mystery how they did it and it’s something researchers have wondered about for the last two decades.”
The researchers found that the Tuvan singers were able to uniquely constrict their vocal tract in two key spots simultaneously – one at the front of their mouth using their tongue and another at the back of their throat. This had the effect of creating the dual sounds.
To figure out the mechanisms involved, researchers at York, including Bergevin and Chandan Narayan from the Faculty of Liberal Arts, recorded the singers in a sound booth and shot a series of images of one the Tuvan performers singing while in an MRI scanner.
Those images were sent to Western Science professor Natasha Mhatre, who helped reconstruct the vocal tract shape using a 3D-reconstruction software called 3DSlicer. Mhatre is a world-leading expert in acoustic and vibratory communication, predominantly in insects and spiders.
“In bioacoustics, morphology can be very powerful in producing unexpected effects and so imaging and understanding the vocal tract was one of our main goals,” said Mhatre, the Canada Research Chair in Invertebrate Neurobiology.
Special to Western NewsHuun-Huur-Tu are a music group from Tuva, a Russian federative republic situated on the Mongolia–Russia border. The most distinctive characteristic of Huun-Huur-Tu’s music is throat singing, in which the singers sing both the note and the drone’s overtone, thus producing two or three notes simultaneously.
Once the vocal tracts were reconstructed, Brad Story of Arizona’s Speech Acoustics and Physiology Lab, modelled and simulated the singing in all the configurations observed in the vocal tract.
Birds and some frogs can produce multiple distinct tones, but only a very few human singers can, including the Tuvans studied here.
In humans, vocal folds make sound by vibrating creating a buzzing noise. How fast or slow the vocal cords vibrate determines whether a high- or low-pitched sound is produced. The faster they vibrate, the higher the pitch of the voice. But they also produce a series of harmonics or ‘overtones.’ The mouth and tongue shape theses overtones, creating resonances at certain frequencies called formants.
Vowels in human speech are determined by the first three formants – F1, F2 and F3. Each formant is usually distinct, but Tuvan singers can merge multiple formants to create one exceedingly sharpened formant and this forms the higher pitched melody with the lowest formant forming the lower rumbling register. Save as PDF
The investigator uses a non-invasive methodology basedon a synchronous recording of voice, laryngographicsignal and subglottal resonance on 2 ‘European’overtone singers and 2 ‘Siberian’ semi-professionalthroat singers. For the upper registers of throat singing an extremely short contacting phase was obtained and SQseems to be appropriate to distinguish between both phonation types. Lower registers share doublet and triplet waveform patterns, but differ significantly in jitter and shimmer rates (j < 0.1; sh < 0.15 for ThS). Other findings are a narrowed bandwidth of a dominant F2 and an ostinato formant between F3 and F4, which are remarkable for all throat singing styles
Khoomei is a unique singing style originating from the republic of Tuva in central Asia. Singers produce two pitches simultaneously: a booming low-frequency rumble alongside a hovering high-pitched whistle-like tone. The biomechanics of this biphonation are not well-understood. Here, we use sound analysis, dynamic magnetic resonance imaging, and vocal tract modeling to demonstrate how biphonation is achieved by modulating vocal tract morphology. Tuvan singers show remarkable control in shaping their vocal tract to narrowly focus the harmonics (or overtones) emanating from their vocal cords. The biphonic sound is a combination of the fundamental pitch and a focused filter state, which is at the higher pitch (1–2 kHz) and formed by merging two formants, thereby greatly enhancing sound-production in a very narrow frequency range. Most importantly, we demonstrate that this biphonation is a phenomenon arising from linear filtering rather than from a nonlinear source.eLife digest
The republic of Tuva, a remote territory in southern Russia located on the border with Mongolia, is perhaps best known for its vast mountainous geography and the unique cultural practice of “throat singing”. These singers simultaneously create two different pitches: a low-pitched drone, along with a hovering whistle above it. This practice has deep cultural roots and has now been shared more broadly via world music performances and the 1999 documentary Genghis Blues.
Despite many scientists being fascinated by throat singing, it was unclear precisely how throat singers could create two unique pitches. Singing and speaking in general involves making sounds by vibrating the vocal cords found deep in the throat, and then shaping those sounds with the tongue, teeth and lips as they move up the vocal tract and out of the body. Previous studies using static images taken with magnetic resonance imaging (MRI) suggested how Tuvan singers might produce the two pitches, but a mechanistic understanding of throat singing was far from complete.
Now, Bergevin et al. have better pinpointed how throat singers can produce their unique sound. The analysis involved high quality audio recordings of three Tuvan singers and dynamic MRI recordings of the movements of one of those singers. The images showed changes in the singer’s vocal tract as they sang inside an MRI scanner, providing key information needed to create a computer model of the process.
This approach revealed that Tuvan singers can create two pitches simultaneously by forming precise constrictions in their vocal tract. One key constriction occurs when tip of the tongue nearly touches a ridge on the roof of the mouth, and a second constriction is formed by the base of the tongue. The computer model helped explain that these two constrictions produce the distinctive sounds of throat singing by selectively amplifying a narrow set of high frequency notes that are made by the vocal cords. Together these discoveries show how very small, targeted movements of the tongue can produce distinctive sounds.Introduction
In the years preceding his death, Richard Feynman had been attempting to visit the small republic of Tuva located in geographic center of Asia (Leighton, 2000). A key catalyst came from Kip Thorne, who had gifted him a record called Melody tuvy, featuring a Tuvan singing in a style known as Khoomei, or Xöömij. Although he was never successful in visiting Tuva, Feynman was nonetheless captivated by Khoomei, which can be best described as a high-pitched tone, similar to a whistle carrying a melody, hovering above a constant booming low-frequency rumble. This is a form of biphonation, or in Feynman’s own words, “a man with two voices”. Khoomei, now a part of the UNESCO Intangible Cultural Heritage of Humanity, is characterized as “the simultaneous performance by one singer of a held pitch in the lower register and a melody … in the higher register” (Aksenov, 1973). How, indeed, does one singer produce two pitches at one time? Even today, the biophysical underpinnings of this biphonic human vocal style are not fully understood.
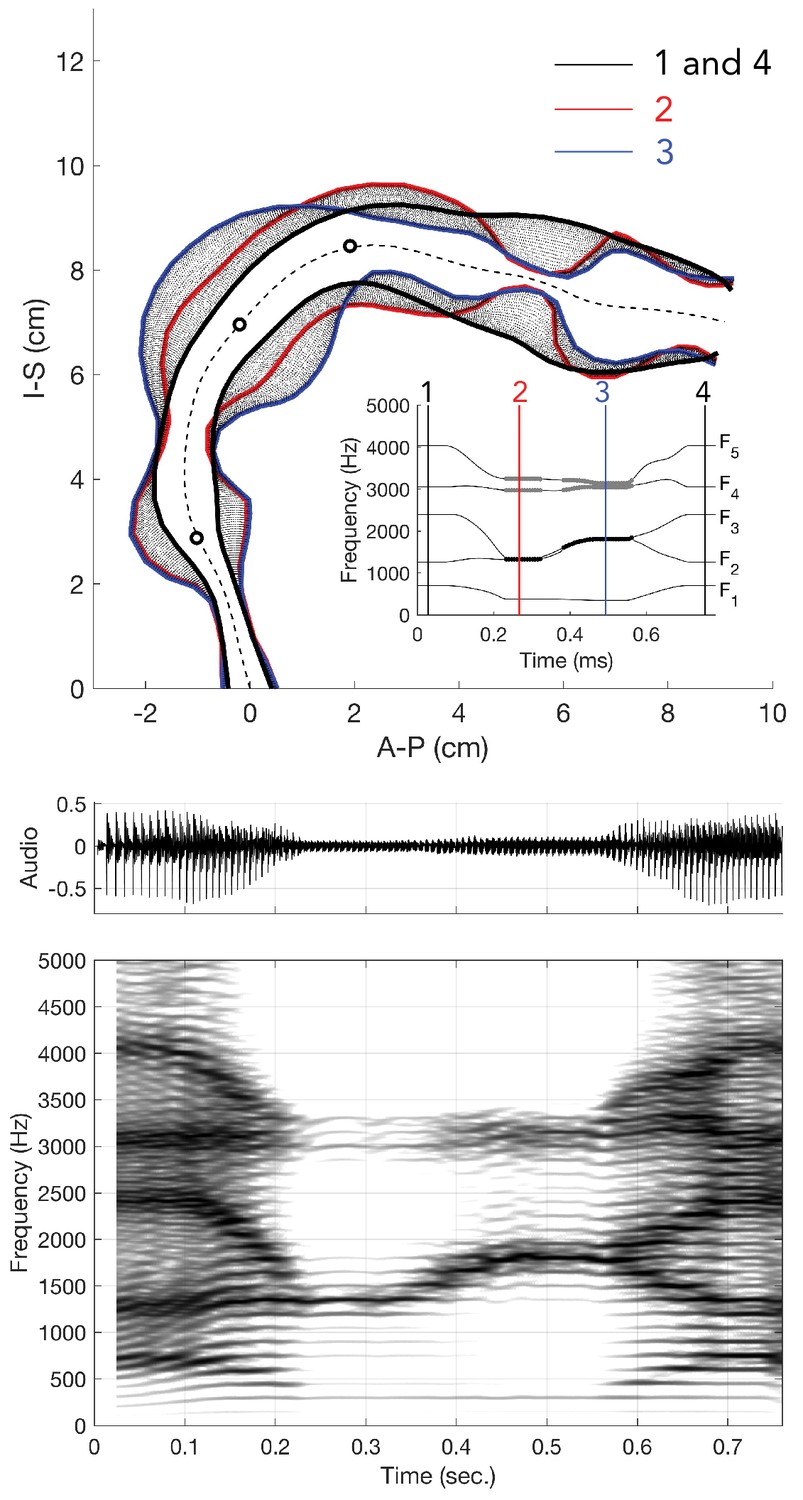
Normally, when a singer voices a song or speech, their vocal folds vibrate at a fundamental frequency (f0), generating oscillating airflow, forming the so-called source. This vibration is not, however, simply sinusoidal, as it also produces a series of harmonics tones (i.e., integer multiples of f0) (Figure 1). Harmonic frequencies in this sound above f0 are called overtones. Upon emanating from the vocal folds, they are then sculpted by the vocal tract, which acts as a spectral filter. The vocal-tract filter has multiple resonances that accentuate certain clusters of overtones, creating formants. When speaking, we change the shape of our vocal tract to shift formants in systematic ways characteristic of vowel and consonant sounds. Indeed, singing largely uses vowel-like sounds (Story, 2016). In most singing, the listener perceives only a single pitch associated with the f0 of the vocal production, with the formant resonances determining the timbre. Khoomei has two strongly emphasized pitches: a low-pitch drone associated with the f0
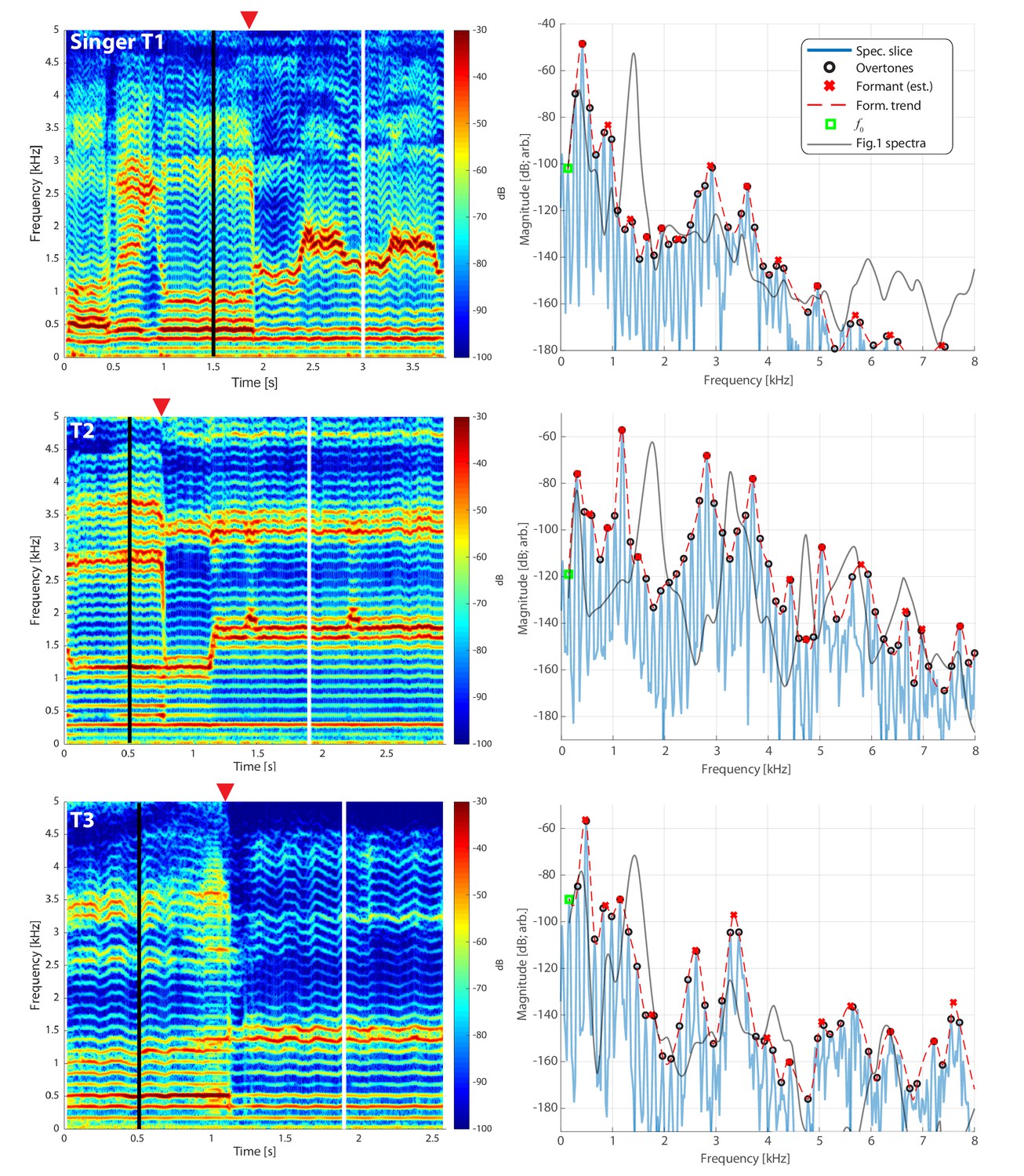
, plus a melody carried by variation in the higher frequency formant that can change independently (Kob, 2004). Two possible loci for this biphonic property are the source and/or the filter. Figure 1
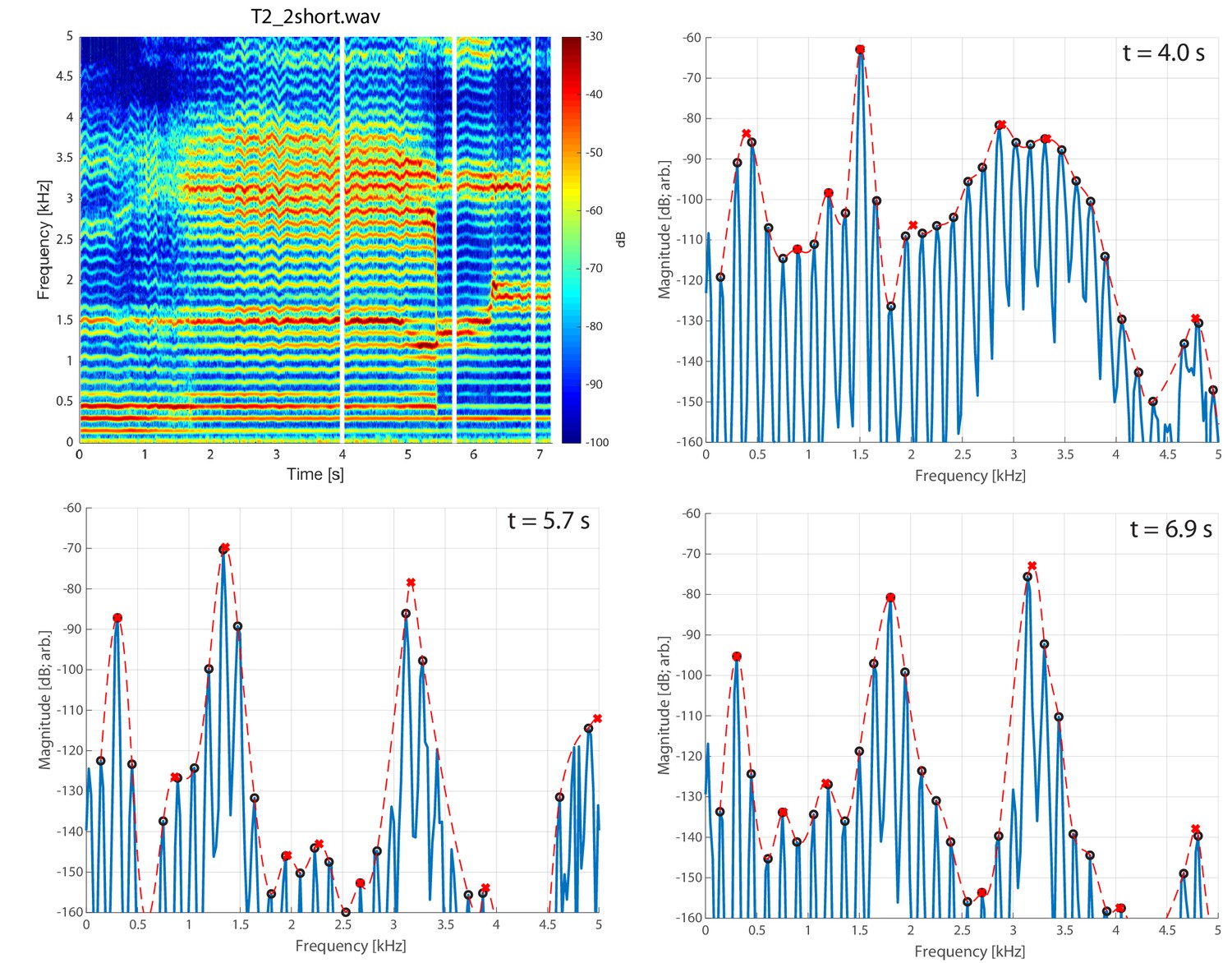
Frequency spectra for three different singers transitioning from normal to biphonic singing. Vertical white lines in the spectrograms (left column) indicate the time point for the associated spectrum in the right column. Transition points from normal to biphonic singing state are denoted by …
A source-based explanation could involve different mechanisms, such as two vibrating nonlinear sound sources in the syrinx of birds, which produce multiple notes that are harmonically unrelated (Fee et al., 1998; Zollinger et al., 2008). Humans however are generally considered to have only a single source, the vocal folds. But there are an alternative possibilities: for instance, the source could be nonlinear and produce harmonically-unrelated sounds. For example, aerodynamic instabilities are known to produce biphonation (Mahrt et al., 2016). Further, Khoomei often involves dramatic and sudden transitions from simple tonal singing to biophonation (see Figure 1 and the Appendix for associated audio samples). Such abrupt changes are often considered hallmarks of physiological nonlinearity (Goldberger et al., 2002), and vocal production can generally be nonlinear in nature (Herzel and Reuter, 1996; Mergell and Herzel, 1997; Fitch et al., 2002; Suthers et al., 2006). Therefore it remains possible that biphonation arises from nonlinear source considerations.
Vocal tract shaping, a filter-based framework, provides an alternative explanation for biphonation. In one seminal study of Tuvan throat singing, Levin and Edgerton examined a wide variety of song types and suggested that there were three components at play. The first two (‘tuning a harmonic’ relative to the filter and lengthening the closed phase of the vocal fold vibration) represented a coupling between source and filter. But it was the third, narrowing of the formant, that appeared crucial. Yet, the authors offered little empirical justification for how these effects are produced by the vocal tract shape in the presented radiographs. Thus it remains unclear how the high-pitched formant in Khoomei was formed (Grawunder, 2009). Another study (Adachi and Yamada, 1999) examined a throat singer using magnetic resonance imaging (MRI) and captured static images of the vocal tract shape during singing. These images were then used in a computational model to produce synthesized song. Adachi and Yamada argued that a “rear cavity” was formed in the vocal tract and its resonance was essential to biphonation. However, their MRI data reveal limited detail since they were static images of singers already in the biphonation state. Small variations in vocal tract geometry can have pronounced effects on produced song (Story et al., 1996) and data from static MRI would reveal little about how and which parts of the vocal tract change shape as the singers transition from simple tonal song to biphonation. To understand which features of vocal tract morphology are crucial to biophonation, a dynamic description of vocal tract morphology would be required.
Here we study the dynamic changes in the vocal tracts of multiple expert practitioners from Tuva as they produce Khoomei. We use MRI to acquire volumetric 3D shape of the vocal tract of a singer during biphonation. Then, we capture the dynamic changes in a midsagittal slice of the vocal tract as singers transition from tonal to biphonic singing while making simultaneous audio recordings of the song. We use these empirical data to guide our use of a computational model, which allows us to gain insight into which features of vocal tract morphology are responsible for the singing phonetics observed during biophonic Khoomei song (e.g., Story, 2016). We focus specifically on the Sygyt (or Sigit) style of Khoomei (Aksenov, 1973).Results
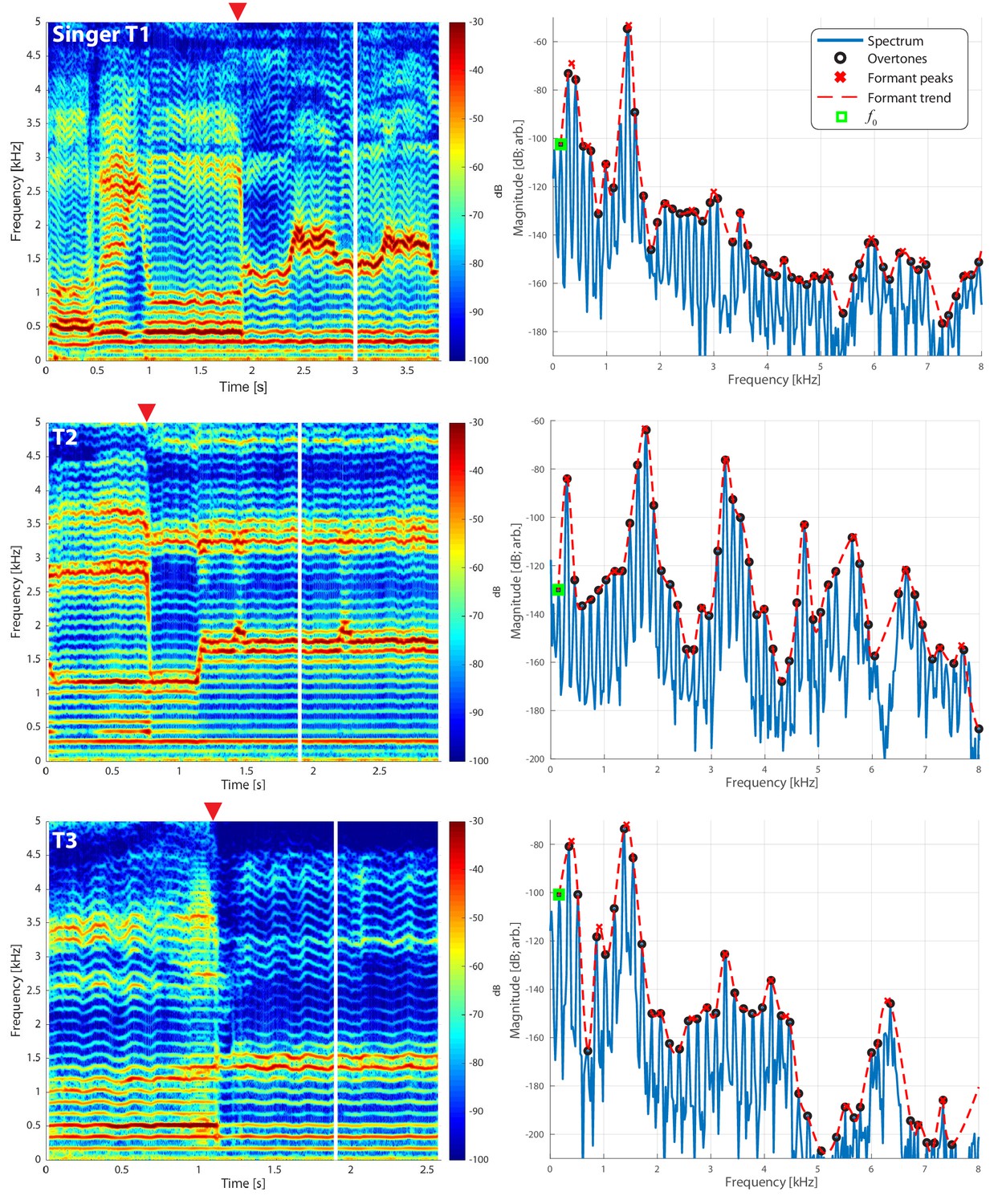
Audio recordings
We made measurements from three Tuvan singers performing Khoomei in the Sygyt style (designated as T1–T3) and one (T4) in a non-Sygyt style. Songs were analyzed using short-time Fourier transforms (STFT), which provide detailed information in both temporal and spectral domains. We recorded the singers transitioning from normal singing into biphonation, Figure 1 showing this transition for three singers. The f0 of their song is marked in the figure (approximately 140 Hz for subject T2, 164 Hz for both T1 and T3) and the overtone structure appears as horizontal bands. Varying degrees of vibrato can be observed, dependent upon the singer (Figure 1; see also longer spectrograms in Appendix 1—figure 6 and Appendix 1—figure 7). Most of the energy in their song is concentrated in the overtones and no subharmonics (i.e., peaks at half-integer multiples of f0
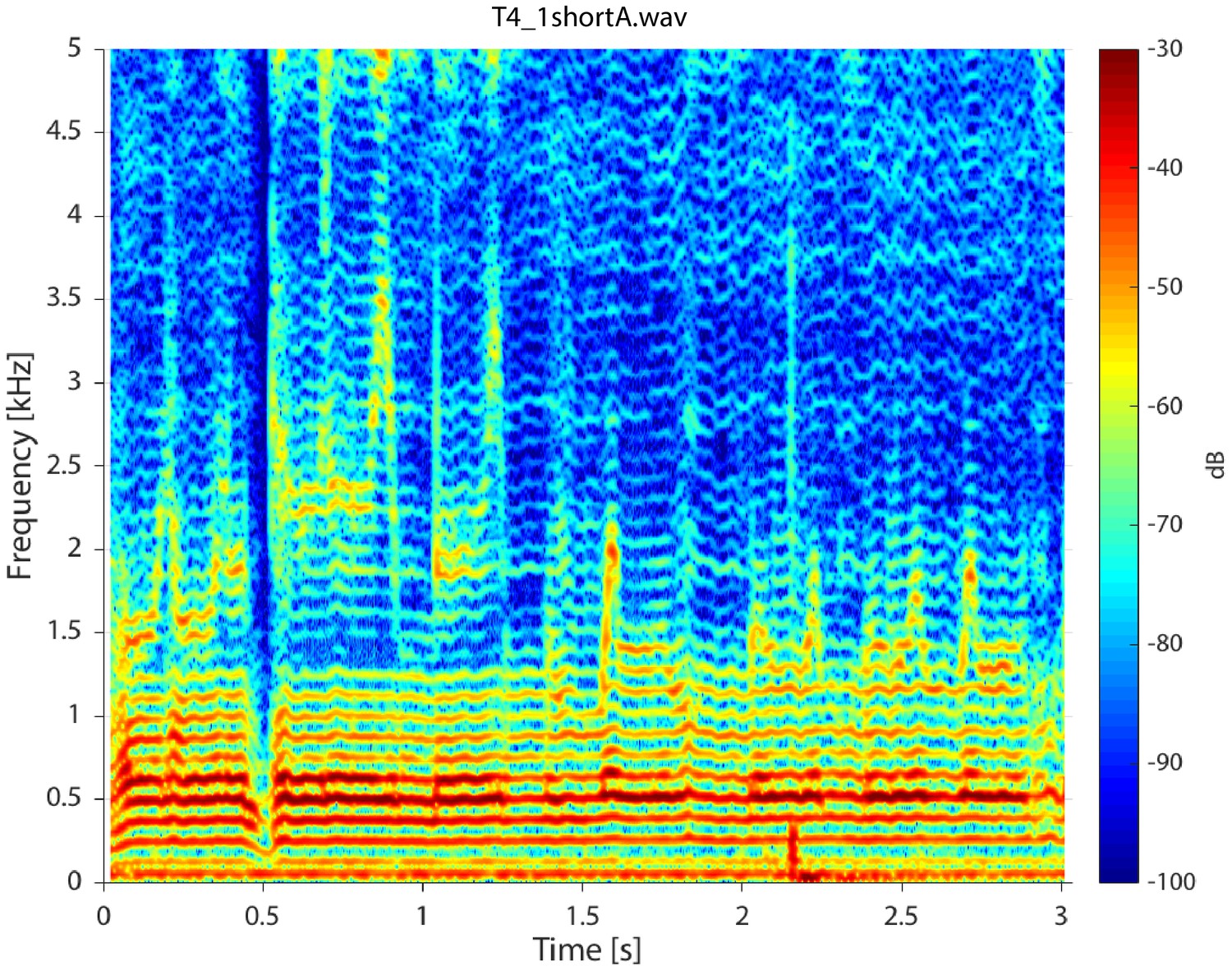
) are observed. In contrast to these three singers, singer T4 performing in a non-Sygyt style exhibited a fundamental frequency of approximately 130 Hz, although significant energy additionally appears around 50–55 Hz, well below an expected subharmonic (Appendix 1—figure 5).
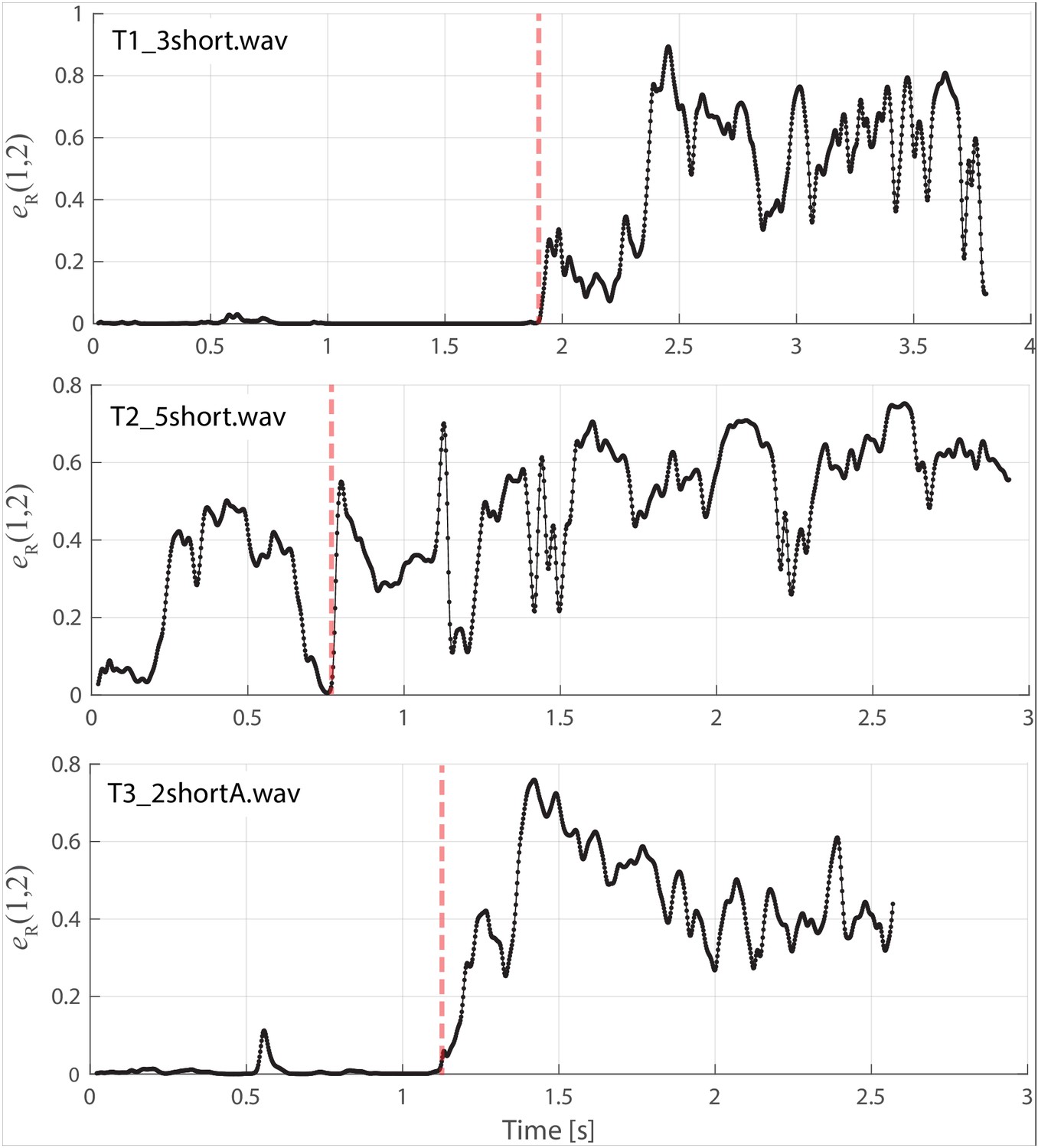
If we take a slice, that is a time-point from the spectrogram and plot the spectrum, we can observe the peaks to infer the formant structure from this representation of the sound (red-dashed lines in Figure 1 and Appendix 1—figure 4). As the singers transition from normal singing to biphonation, we see that the formant structure changes significantly and the positions of formant peaks shift dramatically and rapidly. Note that considering time points before and after the transitions also provides an internal control for both normal and focused song types (Appendix 1—figure 4). Once in the biphonation mode, all three singers demonstrate overtones in a narrow spectral band around 1.5–2 kHz; we refer to this as the focused state. Specifically, Figure 1 shows that not only is just a single or small group of overtones accentuated, but also that nearby ones are greatly attenuated: ±1 overtones are as much 15–35 dB and ±2 overtones are 35–65 dB below the central overtone. Whereas the energy in the low-frequency region associated with the first formant (below 500 Hz) is roughly constant between the normal-singing and focused states, there is a dramatic change in the spectrum for the higher formants above 500 Hz. In normal singing (i.e., prior to the focused state), spectral energy is distributed across several formants between 500 and 4000 Hz. In the focused state after the transition, the energy above 500 Hz becomes narrowly focused in the 1.5–2 kHz region, generating a whistle-like pitch that carries the song melody.
To assess the degree of focus objectively and quantitatively, we computed an energy ratio eR(fL,fH) that characterizes the relative degree of energy brought into a narrow band against the energy spread over the full spectrum occupied by human speech (see Materials and methods). In normal speech and singing, for [fL,fH]=[1,2kHz], typically eR is small (i.e., energy is spread across the spectrum, not focused into that narrow region between 1 and 2 kHz). For the Tuvan singers, prior to a transition into a focused state, eR(1,2) is similarly small. However once the transition occurs (red triangle in Figure 1), those values are large (upwards of 0.5 and higher) and sustained across time (Appendix 1—figure 2 and Appendix 1—figure 3). For one of the singers (T2) the situation was more complex, as he created multiple focused formants (Figure 1 middle panels and Appendix 1—figure 6, Appendix 1—figure 8). The second focused state was not explicitly dependent upon the first: The first focused state clearly moves and transitions between approximately 1.5–2 kHz (by 30%) while the second focused state remains constant at approximately 3–3.5 kHz (changing less than 1%). Thus the focused states are not harmonically related. Unlike the other singers, T2 not only has a second focused state, but also had more energy in the higher overtones (Figure 1). As such, singer T2 also exhibited a different eR
time course, which took on values that could be relatively large even prior to the transition. This may be because he took multiple ways to approach the transition into a focused state (e.g., Appendix 1—figure 9).
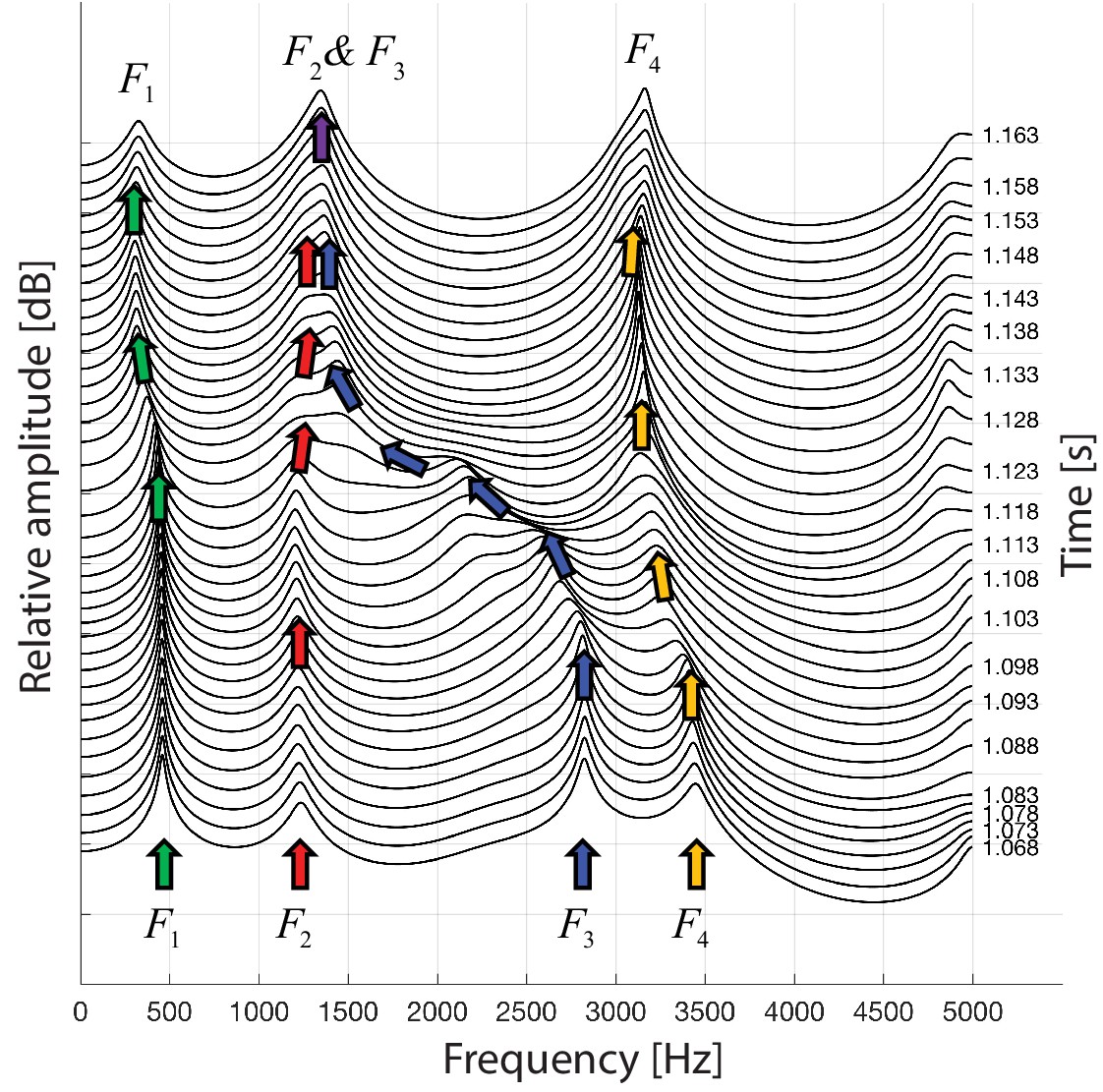
Plotting spectra around the transition from normal to biphonation singing in a waterfall plot indicates that the sharp focused filter is achieved by merging two broader formants together (F2 and F3
in Figure 2; Kob, 2004). This transition into the focused state is fast (∼40–60 ms), as are the shorter transitions within the focused state where the singer melodically changes the filter that forms the whistle-like component of their song (Figure 1, Appendix 1—figure 8). Figure 2
A waterfall plot representing the spectra at different time points as singer T2 transitions from normal singing into biphonation (T2_3short.wav). The superimposed arrows are color-coded to help visualize how the formants change about the transition, chiefly with F3 shifting to merge with F2. This plot also indicates the second focused state …
Vocal tract MRI
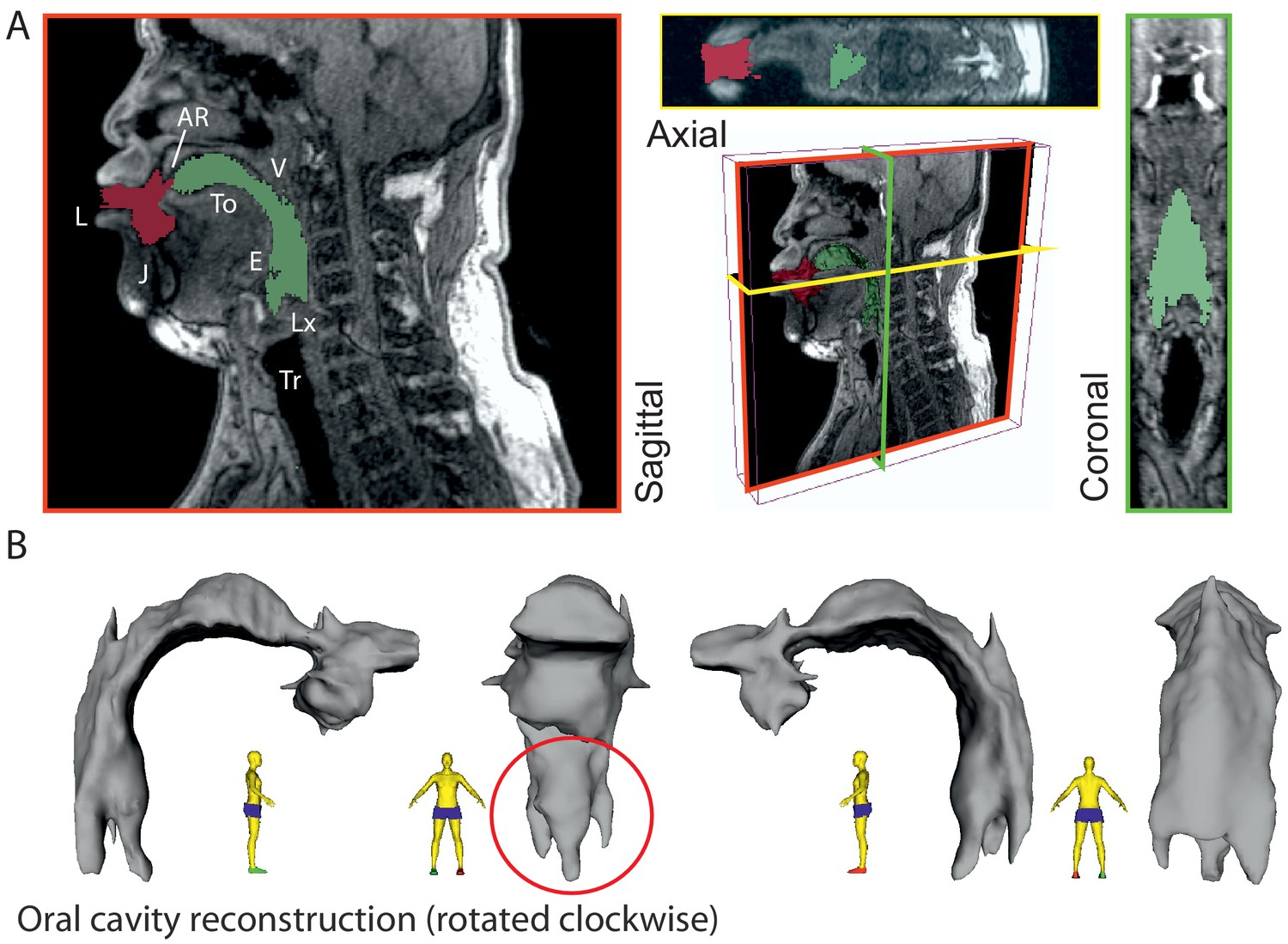
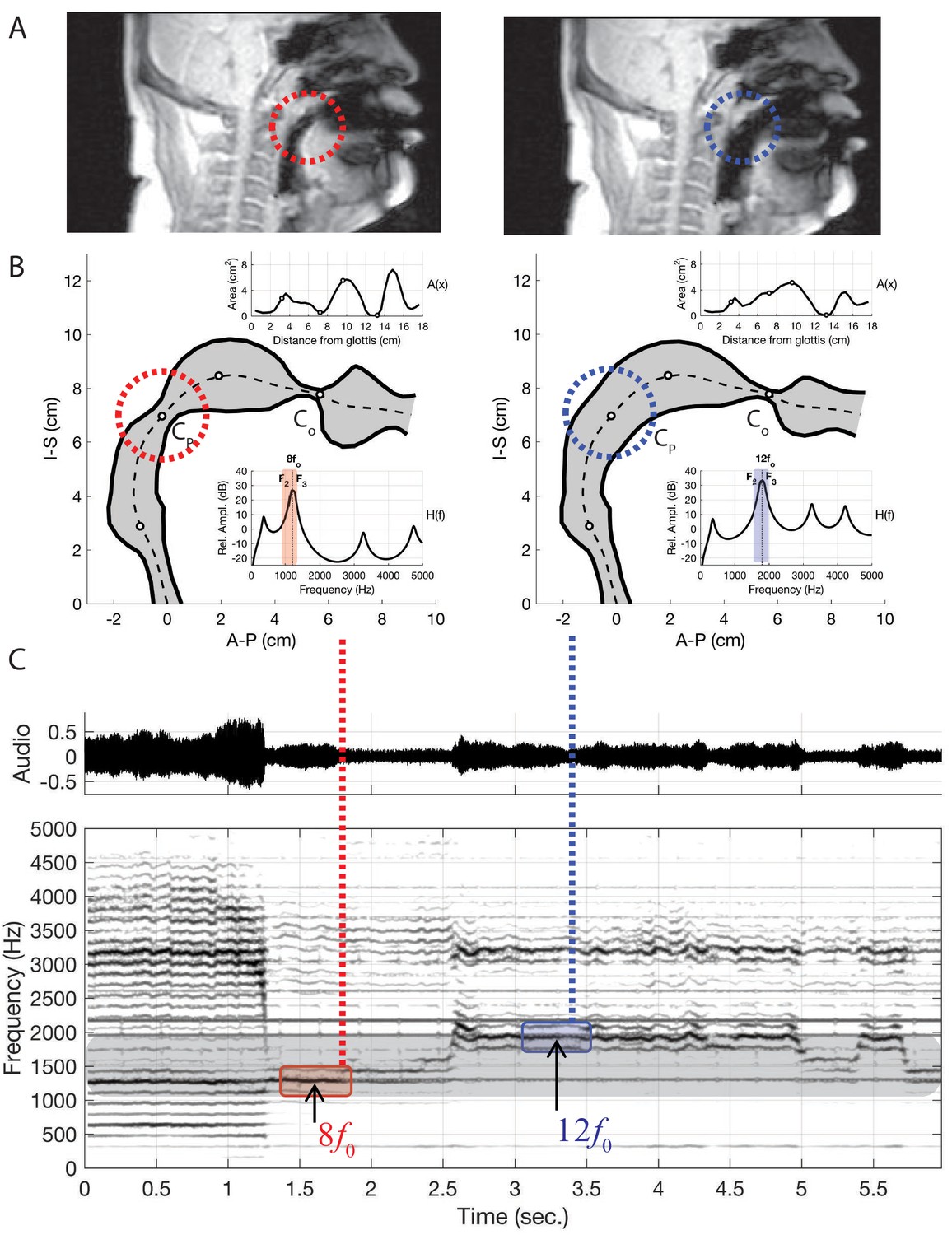
While we can infer the shape of the formants in Khoomei by examining audio recordings, such analysis is not conclusive in explaining the mechanism used to achieve these formants. The working hypothesis was that vocal tract shape determines these formants. Therefore, it was crucial to examine the shape and dynamics of the vocal tract to determine whether the acoustic measurements are consistent with this hypothesis. To accomplish this, we obtained MRI data from one of the singers (T2) that are unique in two regards. First, there are two types of MRI data reported here: steady-state volumetric data Figure 3 and Appendix 1—figure 18) and dynamic midsagittal images at several frames per second that capture changes in vocal tract position (Figure 4A–B and Appendix 1—figure 20). Second is that the dynamic data allow us to examine vocal tract changes as song transitions into a focused state (e.g., Appendix 1—figure 20). Figure 3
3-D reconstruction of volumetric MRI data taken from singer T2 (Run3; see Appendix, including Appendix 1—figure 18). (A) Example of MRI data sliced through three different planes, including a pseudo-3D plot. Airspaces were determined manually (green areas behind tongue tip, red for beyond). Basic labels are …
Figure 4
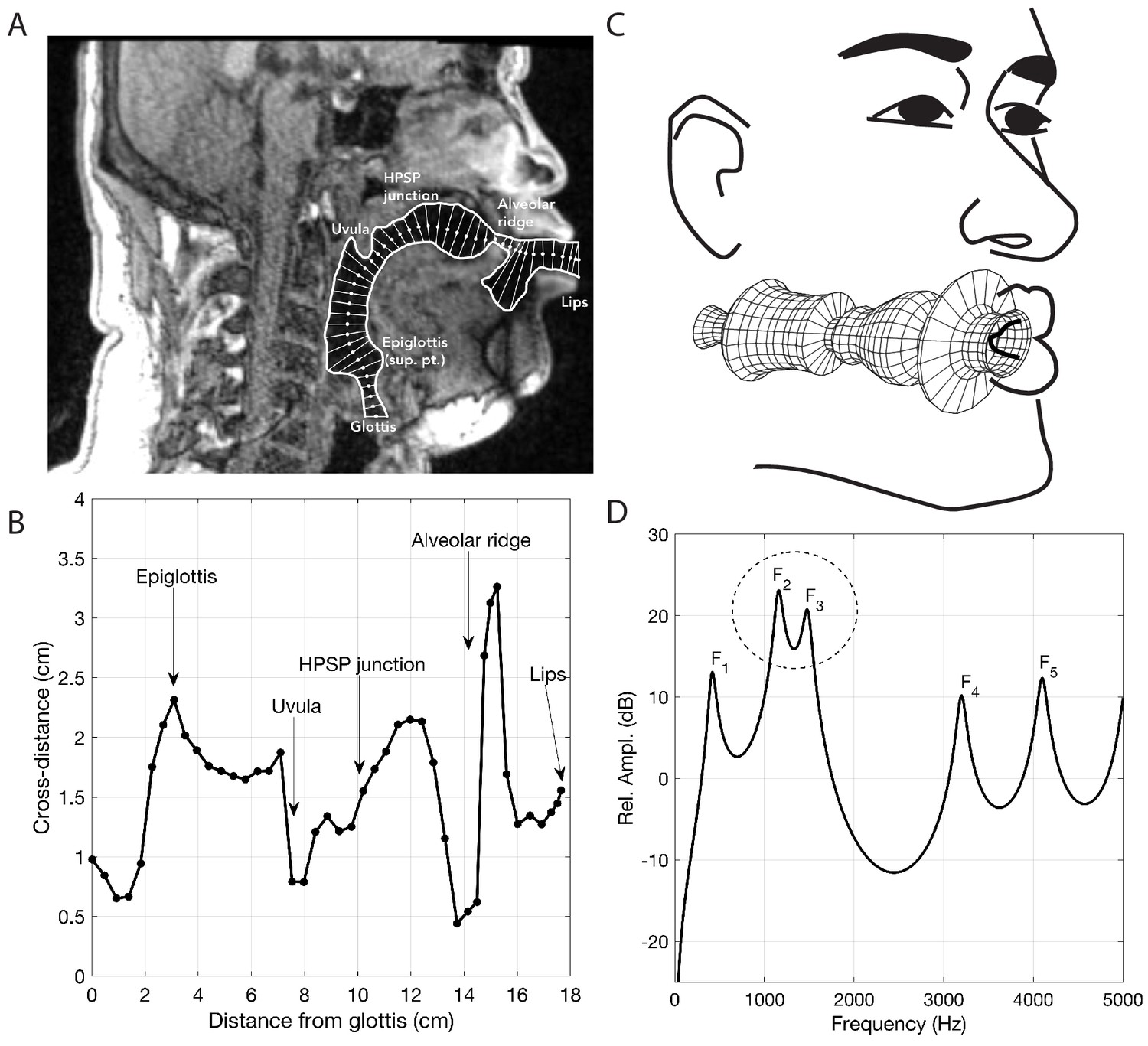
Analysis of vocal tract configuration during singing. (A) 2D measurement of tract shape. The inner and outer profiles were manually traced, whereas the centerline (white dots) was found with an iterative bisection technique. The distance from the inner …
The human vocal tract begins at the vocal folds and ends at the lips. Airflow produced by the vocal cords sets the air-column in the tract into vibration, and its acoustics determine the sound that emanates from the mouth. The vocal tract is effectively a tube-like cavity whose shape can be altered by several articulators: the jaw, lips, tongue, velum, epiglottis, larynx and trachea (Figure 4C). Producing speech or song requires that the shape of the vocal tract, and hence its acoustics, are precisely controlled (Story, 2016).
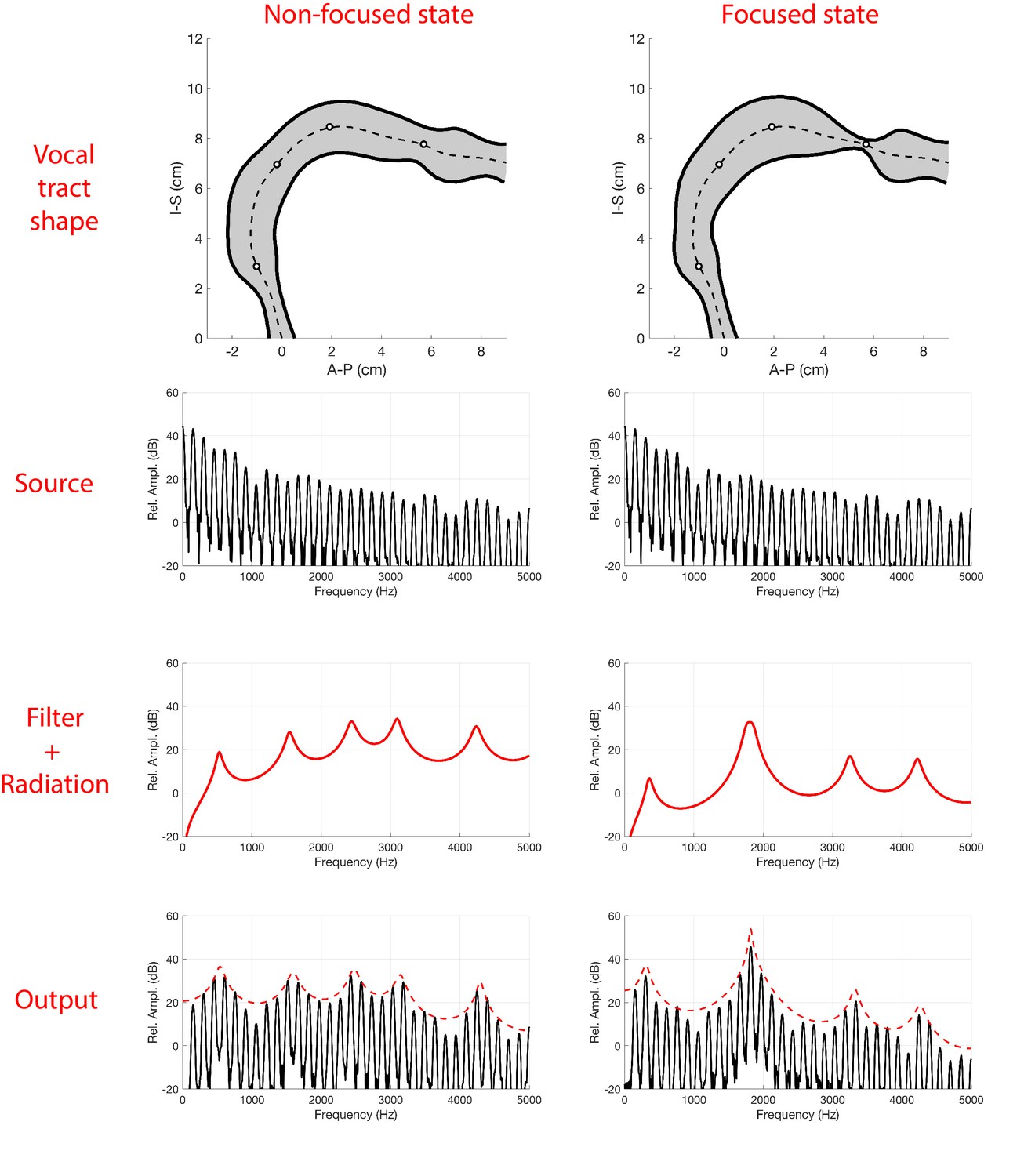
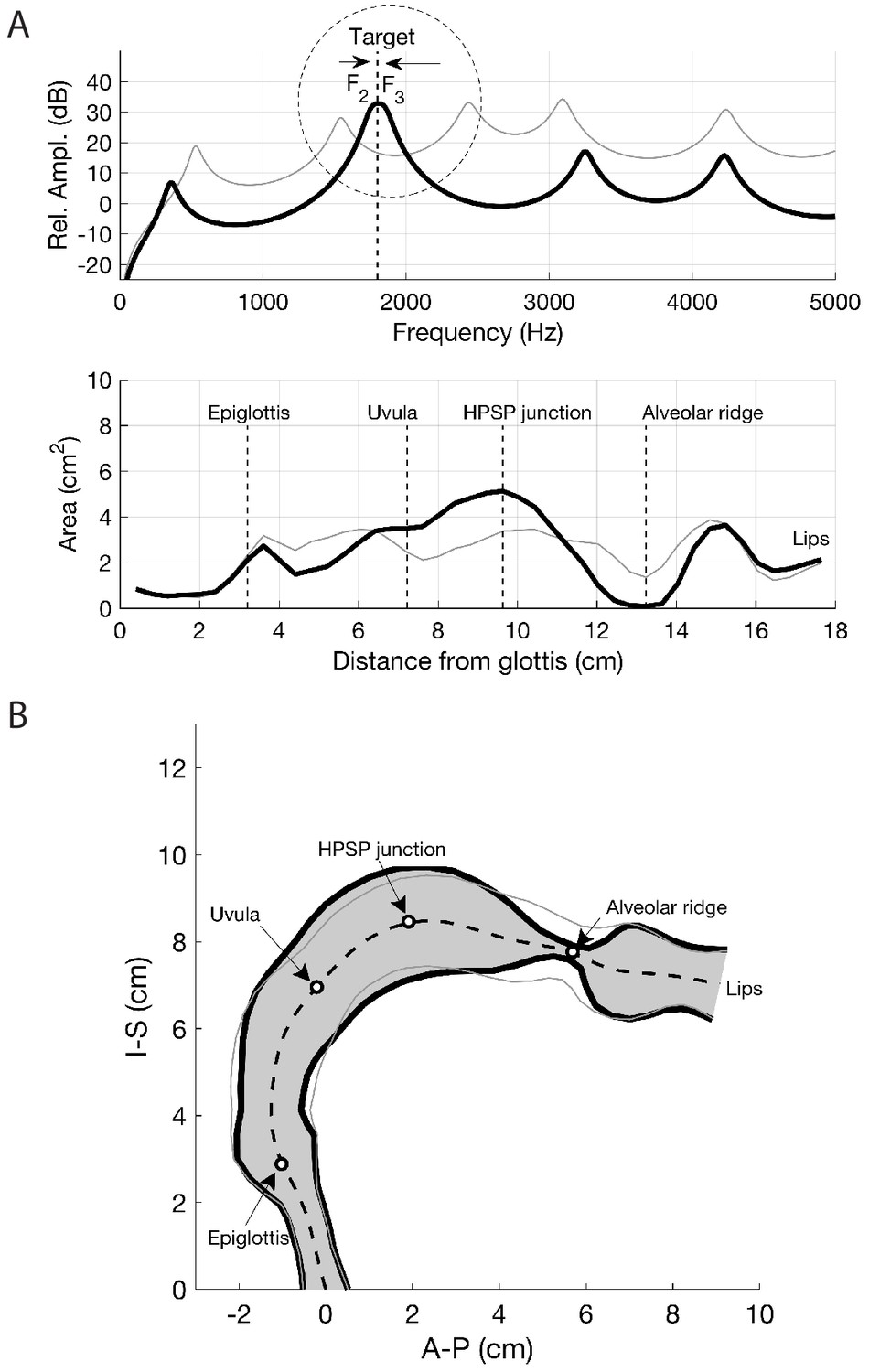
Several salient aspects of the vocal tract during the production of Khoomei can be observed in the volumetric MRI data. The most important feature however, is that there are two distinct and relevant constrictions when in the focused state, corresponding roughly to the uvula and alveolar ridge. Additionally, the vocal tract is expanded in the region just anterior to the alveolar ridge (Figure 4A). The retroflex position of the tongue tip and blade produces a constriction at 14 cm, and also results in the opening of this sublingual space. It is the degree of constriction at these two locations that is hypothesized to be the primary mechanism for creating and controlling the frequency at which the formant is focused.
Modeling
Having established that the shape of vocal tract during Khoomei does indeed have two constrictions, consistent with observations from other groups, the primary goals of our modeling efforts were to use the dynamic MRI data as morphological benchmarks and capture the merging of formants to create the focused states as well as the dynamic transitions into them. Our approach was to use a well-established linear “source/filter” model (e.g., Stevens, 2000) that includes known energy losses (Sondhi and Schroeter, 1987; Story et al., 2000; Story, 2013). Here, the vibrating vocals folds act as the broadband sound source (with the f0
and associated overtone cascade), while resonances of the vocal tract, considered as a series of 1-D concatenated tubes of variable uniform radius, act as a primary filter. We begin with a first order assumption that the system behaves linearly, which allows us for a simple multiplicative relationship between the source and filter in the spectral domain (e.g., Appendix 1—figure 10).
Acoustic characteristics of the vocal tract can be captured by transforming the three-dimensional configuration (Figure 3) into a tube with variation in its cross-sectional area from the glottis to the lips (Figure 4 and Figure 5). This representation of the vocal tract shape is called an area function, and allows for calculation of the corresponding frequency response function (from which the formant frequencies can be determined) with a one-dimensional wave propagation algorithm. Although the area function can be obtained directly from a 3D vocal tract reconstruction (e.g., Story et al., 1996), the 3D reconstructions of the Tuvan singer’s vocal tract were affected by a large shadow from a dental post (e.g., see Figure 4) and were not amenable to detailed measurements of cross-sectional area. Instead, a cross-sectional area function was measured from the midsagittal slice of the 3D image set (see Materials and methods and Appendix for details). Thus, the MRI data provided crucial bounds for model parameters: the locations of primary constrictions and thereby the associated area functions. Figure 5
Results of changing vocal tract morphology in the model by perturbing the baseline area function A0(x)
to demonstrate the merging of formants F2
and F3
, atop two separate overtones as apparent in the two columns of panels A and B.
(A) The frames from dynamic MRI with red and blue dashed circles highlighting the location of the key vocal tract constrictions. (B) Model-based vocal tract shapes stemming from the MRI data, …
The frequency response functions derived from the above static volumetric MRI data (e.g., Figure 4D) indicate that two formants F2 and F3 cluster together, thus enhancing both their amplitudes. Clearly, if F2 and F3
could be driven closer together in frequency, they would merge and form a single formant with unusually high amplitude. We hypothesize that this mechanism could be useful for effectively amplifying a specific overtone, such that it becomes a prominent acoustic feature in the sound produced by a singer, specifically the high frequency component of Khoomei.
Next, we used the model in conjunction with time-resolved MRI data to investigate how the degree of constriction and expansion at different locations along the vocal tract axis could be a mechanism for controlling the transition from normal to overtone singing and the pitch while in the focused state. These results are summarized in Figure 5 (further details are in the Appendix). While the singers are in the normal song mode, there are no obvious strong constrictions in their vocal tracts (e.g., Appendix 1—figure 11). After they transition, in each MRI from the focused state, we observe a strong constriction near the alveolar ridge. We also observe a constriction near the uvula in the upper pharynx, but the degree of constriction here varies. If we examine the simultaneous audio recordings, we find that variations in this constriction are co-variant with the frequency of the focused formant. From this, we surmise that the mechanism for controlling the enhancement of voice harmonics is the degree of constriction near the alveolar ridge in the oral cavity (labeled CO in Figure 5), which affects the proximity of F2 and F3 to each other (Appendix 1—figure 12). Additionally, the degree of constriction near the uvula in the upper pharynx (CP) controls the actual frequency at which F2 and F3 converge (Appendix 1—figure 13). Other parts of the vocal tract, specifically the expansion anterior to CO
, may also contribute since they also show small co-variations with the focused formant frequency (Appendix 1—figure 14). Further, a dynamic implementation of the model, as shown in Appendix 1—figure 14, reasonably captures the rapid transition into/out of the focused state as shown in Figure 1. Taken together, the model confirms and explains how these articulatory changes give rise to the observed acoustic effects.
To summarize, an overtone singer could potentially ‘play’ (i.e., select) various harmonics of the voice source by first generating a tight constriction in the oral cavity near the alveolar ridge, and then modulating the degree of constriction in the uvular region of the upper pharynx to vary the position of the focused formant, thereby generating a basis for melodic structure.Discussion
This study has shown that Tuvan singers performing Sygyt-style Khoomei exercise precise control of the vocal tract to effectively merge multiple formants together. They morph their vocal tracts so to create a sustained focused state that effectively filters an underlying stable array of overtones. This focused filter greatly accentuates energy of a small subset of higher order overtones primarily in the octave-band spanning 1–2 kHz, as quantified by an energy ratio eR(1,2)
. Some singers are even capable of producing additional foci at higher frequencies. Below, we argue that a linear framework (i.e., source/filter model, Stevens, 2000) appears sufficient to capture this behavior including the sudden transitions into a focused state, demonstrating that nonlinearities are not a priori essential. That is, since the filter characteristics are highly sensitive to vocal tract geometry, precise biomechanical motor control of the singers is sufficient to achieve a focused state without invoking nonlinearities or a second source as found in other vocalization types (e.g., Herzel and Reuter, 1996; Fee et al., 1998). Lastly, we describe several considerations associated with how focused overtone song produces such a salient percept by virtue of a pitch decoherence.
Source or filter?
The notion of a focused state is mostly consistent with vocal tract filter-based explanations for biphonation in previous studies (e.g., Bloothooft et al., 1992; Edgerton et al., 1999; Adachi and Yamada, 1999; Grawunder, 2009), where terms such as an ‘interaction of closely spaced formants’, ‘reinforced harmonics’, and ‘formant melting’ were used. In addition, the merging of multiple formants is closely related to the ‘singer’s formant’, which is proposed to arise around 3 kHz due to formants F3–F5 combining (Story, 2016), though this is typically broader and less prominent than the focused states exhibited by the Tuvans. Our results explain how this occurs and are also broadly consistent with Adachi and Yamada (1999) in that a constricted ‘rear cavity’ is crucial. However, we find that this rear constriction determines the pitch of the focused formant, whereas it is the ‘front cavity’ constriction near the alveolar ridge that produces the focusing effect (i.e., merging of formants F2 and F3
).
Further, the present data appear in several ways inconsistent with conclusions from previous studies of Khoomei, especially those that center on effects that arise from changes in the source. Three salient examples are highlighted. First, we observed overtone structure to be highly stable, though some vibrato may be present. This contrasts the claim by Levin and Edgerton (1999) that “(t)o tune a harmonic, the vocalist adjusts the fundamental frequency of the buzzing sound produced by the vocal folds, so as to bring the harmonic into alignment with a formant’. That is, we see no evidence for the overtone ‘ladder’ being lowered or lifted as they suggested (note in Figure 1, f0
is held nearly constant). Further, this stability argues against a transition into a different mode of glottal pulse generation, which could allow for a ‘second source’ (Mergell and Herzel, 1997). Second, a single sharply defined harmonic alone is not sufficient to get the salient perception of a focused state, as had been suggested by Levin and Edgerton (1999). Consider Appendix 1—figure 9, especially at the 4 s mark, where the voicing is ‘pressed’. Pressed phonation, also referred to as ventricular voice, occurs when glottal flow is affected by virtue of tightening the laryngeal muscles such that the ventricular folds are brought into vibration. This has the perceptual effect of adding a degree of roughness to the voice sound (Lindestad et al., 2001; Edmondson and Esling, 2006). There, a harmonic at 1.51 kHz dominates (i.e., the two flanking overtones are approximately 40 dB down), yet the song has not yet perceptibly transitioned. It is not until the cluster of overtones at 3–3.5 kHz is brought into focus that the perceptual effect becomes salient, perhaps because prior to the 5.3 s mark the broadband nature of those frequencies effectively masks the first focused state. Third, we do not observe subharmonics, which contrasts a prior claim (Lindestad et al., 2001) that ”(t)his combined voice source produces a very dense spectrum of overtones suitable for overtone enhancement’. However, that study was focused on a different style of song called ‘Kargyraa’, which does not exhibit as clearly a focused state as in Sygyt.
Linear versus nonlinear mechanisms
An underlying biophysical question is whether focused overtone song arises from inherently linear or nonlinear processes. Given that Khoomei consists of the voicing of two or more pitches at once and exhibits dramatic and fast transitions from normal singing to biphonation, nonlinear phenomena may seem like an obvious candidate (Herzel and Reuter, 1996). It should be noted that Herzel and Reuter (1996) go so far to define biphonation explicitly through the lens of nonlinearity. We relax such a definition and argue for a perceptual basis for delineating the boundaries of biphonation. Certain frog species exhibit biphonation, and it has been suggested that their vocalizations can arise from complex nonlinear oscillatory regimes of separate elastically coupled masses (Suthers et al., 2006). Further, the appearance of abrupt changes in physiological systems (as seen in Figure 1) has been argued to be a flag for nonlinear mechanisms (Goldberger et al., 2002); for example, by virtue of progression through a bifurcation.
Our results present two lines of evidence that argue against Sygyt-style Khoomei arising primarily from a nonlinear process. First, the underlying harmonic structure of the vocal fold source appears highly stable through the transition into the focused state (Figure 1). There is little evidence of subharmonics. A source spectral structure that is comprised of an f0
and integral harmonics would suggest a primarily linear source mechanism. Second is that our modeling efforts, which are chiefly linear in nature, reasonably account for the sudden and salient transition. That is, the model is readily sufficient to capture the characteristic that small changes in the vocal tract can produce large changes in the filter. Thereby, precise and fast motor control of the articulators in a linear framework accounts for the transitions into and out of the focused state. Thus, in essence, Sygyt-style Khoomei could be considered a linear means to achieve biphonation. Connecting back to nonlinear phonation mechanisms in non-mammals, our results provide further context for how human song production and perception may be similar and/or different relative to that of non-humans (e.g., Doolittle et al., 2014; Kingsley et al., 2018).
Nevertheless, features that appear transiently in spectrograms do provide hints of source nonlinearity, such as the brief appearance of subharmonics in some instances (Appendix 1—figure 15B). This provides an opportunity to address the limitations of the current modeling efforts and to highlight future considerations. We suggest that further analysis (e.g., Theiler et al., 1992; Tokuda et al., 2002; Kantz and Schreiber, 2004) of Khoomei audio recordings may help to inform the model and might better capture focused filter sharpness and the origin of secondary focused states. Several potential areas for improvement are: nonlinear source–filter coupling (Titze et al., 2008); a detailed model of glottal dynamics (e.g., ratio of open/closed phases in glottal flow [Grawunder, 2009; Li and Hou, 2017], and periodic vibrations in f0
); inclusion of piriform sinuses as side-branch resonators (Dang and Honda, 1997; Titze and Story, 1997); inclusion of the 3-D geometry; and detailed study of the front cavity (e.g., lip movements) that may be used by the singer to maintain control of the focused state and to make subtle manipulations.
Perceptual consequences of overtone focusing
Although this study did not directly assess the percept associated with these vocal productions, the results raise pressing questions about how the spectro-temporal signatures of biphonic Khoomei described here create the classical perception of Sygyt-style Khoomei as two distinct sounds (Aksenov, 1973). The first, the low-pitched drone, which is present during both the normal singing and the focused-state biphonation intervals, reflects the pitch associated with f0, extracted from the harmonic representation of the stimulus. It is well established that the perceived pitch of a broadband sound comprised of harmonics reflects the f0 derived primarily from the perceptually resolved harmonics up to about 10f0 (Bernstein and Oxenham, 2003). The frequency resolution of the peripheral auditory system is such that these low-order harmonics are individually resolved by the cochlea, and it appears that such filtering is an important prerequisite for pitch extraction associated with that common f0. The second sound, the high-pitched melody, is present only during the focused-state intervals and probably reflects a pitch associated with the focused formant. An open question, however, is why this focused formant would be perceived incoherently as a separate pitch (Shamma et al., 2011), when it contains harmonics at multiples of f0
. The auditory system tends to group together concurrent harmonics into a single perceived object with a common pitch (Roberts et al., 2015), and the multiple formants of a sung or unsung voice are not generally perceived as separate sounds from the low harmonics.
The fact that the focused formant is so narrow apparently leads the auditory system to interpret this sound as if it were a separate tone, independent of the low harmonics associated with the drone percept, thereby effectively leading to a pitch decoherence. This perceptual separation could be attributable to a combination of both bottom-up (i.e., cochlear) and top-down (i.e., perceptual) factors. From the bottom-up standpoint, even if the focused formant is broad enough to encompass several harmonic components, the fact that it consists of harmonics at or above 10 f0 (i.e., the 1500 Hz formant frequency represents the 10th harmonic of a 150 Hz f0) means that these harmonics will not be spectrally resolved by cochlear filtering (Bernstein and Oxenham, 2003). Instead, the formant will be represented as a single spectral peak, similar to the representation of a single pure tone at the formant frequency. Although the interaction of harmonic components at this cochlear location will generate amplitude modulation at a rate equal to the f0 (Plack and Oxenham, 2005), it has been argued that a common f0 is a weak cue for binding low- and high-frequency formants (Culling and Darwin, 1993). Rather, other top-down mechanisms of auditory-object formation may play a more important role in generating a perception of two separate objects in Khoomei. For example, the rapid onsets of the focused formant may enhance its perceptual separation from the constant drone (Darwin, 1984). Further, the fact that the focused formant has a variable frequency (i.e., frequency modulation, or FM) while the drone maintains a constant f0
is another difference that could facilitate their perceptual separation. Although it has been argued that FM differences between harmonic sounds generally have little influence on their perceived separation (Darwin, 2005), others have reported enhanced separation in the special case in which one complex was static and the other had applied FM (Summerfield and Culling, 1992) – similar to the first and second formants during the Tuvan focused state.
The perceptual separation of the two sounds in the Tuvan song might be further affected by a priori expectations about the spectral qualities of vocal formants (Billig et al., 2013). Because a narrow formant occurs so rarely in natural singing and speech, the auditory system might be pre-disposed against perceiving it as a phonetic element, limiting its perceptual integration with the other existing formants. Research into ‘sine-wave speech’ provides some insights into this phenomenon. When three or four individual frequency-modulated sinusoids are presented at formant frequencies in lieu of natural formants, listeners can, with sufficient training, perceive the combination as speech (Remez et al., 1981). Nevertheless, listeners largely perceive these unnatural individual pure tones as separate auditory objects (Remez et al., 2001), much like the focused formant in Khoomei. Further research exploring these considerations would help close the production–perception circle underlying the unique percept arising from Tuvan throat song.Materials and methods
Recordings were made at York University (Toronto, ON, Canada) in a double-walled acoustic isolation booth (IAC) using a Zoom H5 24-bit digital recorder and an Audio-Technica P48 condenser microphone. A sample rate of 96 kHz was used. Spectral analysis was done using custom-coded software in Matlab. Spectrograms were typically computed using 4096 point window segments with 95% fractional overlap and a Hamming window. Harmonics (black circles in Figure 1) were estimated using a custom-coded peak-picking algorithm. Estimated formant trends (red dashed lines in Figure 1) were determined using a lowpass interpolating filter built into Matlab’s digital signal processing toolbox with a scaling factor of 10. From this trend, the peak-picking was reapplied to determine ‘formant’ frequencies (red ‘x’s in Figure 1). This process could be repeated across the spectrogram to track overtone and formant frequency/strength effectively, as shown in Appendix 1—figure 1.
To quantify the focused states, we developed a dimension-less measure eR(fL,fH) to represent the energy ratio of that spanning a frequency range fH−fL relative to the entire spectral output. This can be readily computed from the spectrogram data as follows. First take a ‘slice’ from the spectrogram and convert spectral magnitude to linear ordinate and square it (as intensity is proportional to pressure squared). Then integrate across frequency, first for a limited range spanning [fL,fH] (e.g., 1–2 kHz) and then for a broader range of [0,fmax] (e.g., 0–8 kHz; 8 kHz is a suitable maximum as there is little acoustic energy in vocal output above this frequency). The ratio of these two is then defined as eR
, and takes on values between 0 and 1. This can be expressed more explicitly as: (1) eR(fL,fH)=(∫fHfLP(f)df∫fmax0P(f)df)2
where P is the magnitude of the scaled sound pressure, f is frequency, and fL and fH are filter limits for considering the focused state. The choice of [fL,fH]=[1,2] kHz has the virtue of spanning an octave, which also closely approximates the ‘seventh octave’ from about C6 to C7. eR did not depend significantly upon the length of the fast Fourier transform (FFT) window. Values of eR
MRI images were acquired at the York MRI Facility on a 3.0 Tesla MRI scanner (Siemens Magnetom TIM Trio, Erlangen, Germany), using a 12-channel head coil and a neck array. Data were collected with the approval of the York University Institutional Review Board. The participant was fitted with an MRI compatible noise-cancelling microphone (Optoacoustics, Mazor, Israel) mounted directly above the lips. The latency of the microphone and noise-cancelling algorithm was 24 ms. Auditory recordings were made in QuickTime on an iMac during the scans to verify performance.
Images were acquired using one of two paradigms, static or dynamic. Static images were acquired using a T1-weighted 3D gradient echo sequence in the sagittal orientation with 44 slices centered on the vocal tract, TR = 2.35 ms, TE = 0.97 ms, flip angle = 8 degrees, FoV = 300 mm, and a voxel dimension of 1.2 × 1.2×1.2 mm. Total acquisition time was 11 s. The participant was instructed to begin singing a tone, and to hold it in a steady state for the duration of the scan. The scan was started immediately after the participant began to sing and had reached a steady state. Audio recordings verified a consistent tone for the duration of the scan. Dynamic images were acquired using a 2D gradient echo sequence. A single 10.0 mm thick slice was positioned in a sagittal orientation along the midline of the vocal tract, TR = 4.6 ms, TE = 2.04 ms, flip angle = 8 degrees, FoV = 250 mm, and a voxel dimension of 2.0 × 2.0×10.0 mm. One hundred measurements were taken for a scan duration of 27.75 s. The effective frame rate of the dynamic images was 3.6 Hz. Audio recordings were started just prior to scanning. Only subject T2 participated in the MRI recordings. The participant was instructed to sing a melody for the duration of the scan, and took breaths as needed.
For segmentation (Figure 3), 3D MRI images (Run1; see Appendix) were loaded into Slicer (version 4.6.2 r25516). The air-space in the oral cavity was manually segmented using the segmentation module, identified and painted in slice by slice. Careful attention was paid to the parts of the oral cavity that were affected by the artifact from the dental implant. The air cavity was manually repainted to be approximately symmetric in this region using the coronal and axial view (Figure 3A). Once completely segmented, the sections were converted into a 3D model and exported as a STL file. This mesh file was imported into MeshLab (v1.3.4Beta) for cleaning and repairing the mesh. The surface of the STL was converted to be continuous by removing non-manifold faces and then smoothed using depth and Laplacian filters. The mesh was then imported into Meshmixer where further artifacts were removed. This surface-smoothed STL file was finally reimported into Slicer, generating the display in Figure 3B.
Measurement of the cross-distance function is illustrated in Figure 4. The inner and outer profiles of the vocal tract were first determined by manual tracing of the midsagittal image. A 2D iterative bisection algorithm (Story, 2007) was then used to find the centerline within the profiles extending from the glottis to the lips, as shown by the white dots in Figure 4A. Perpendicular to each point on the centerline, the distance from the inner to outer profiles was measured to generate the cross-distance function shown in Figure 4B; the corresponding locations of the anatomic landmarks shown in the midsagittal image are also indicated on the cross-distance function.
The cross-distance function, D(x), can be transformed to an approximate area function, A(x), with the relation A(x)=kDα(x), where k and α are a scaling factor and exponent, respectively. If the elements of D(x) are considered to be diameters of a circular cross-section, k=(π/4) and α=2. Although other values of k and α have been proposed to account for the complex shape of the vocal tract cross-section (Heinz and Stevens, 1964; Lindblom and Sundberg, 1971; Mermelstein, 1973), there is no agreement on a fixed set of numbers for each parameter. Hence, the circular approximation was used in this study to generate an estimate of the area function. In Figure 4C, the area function is plotted as its tubular equivalent, where the radii D(x)/2
were rotated about an axis to generate circular sections from the glottis to the lips.
The associated frequency response of that area function is shown in Figure 4D and was calculated with a transmission line approach (Sondhi and Schroeter, 1987; Story et al., 2000), which included energy losses due to yielding walls, viscosity, heat conduction, and acoustic radiation at the lips. Side branches such the piriform sinuses were not considered in detail in this study. The first five formant frequencies (resonances), F1,…,F5
, were determined by finding the peaks in the frequency response functions with a peak-picking algorithm (Titze et al., 1987) and are located at 400, 1065, 1314, 3286, and 4029 Hz, respectively.
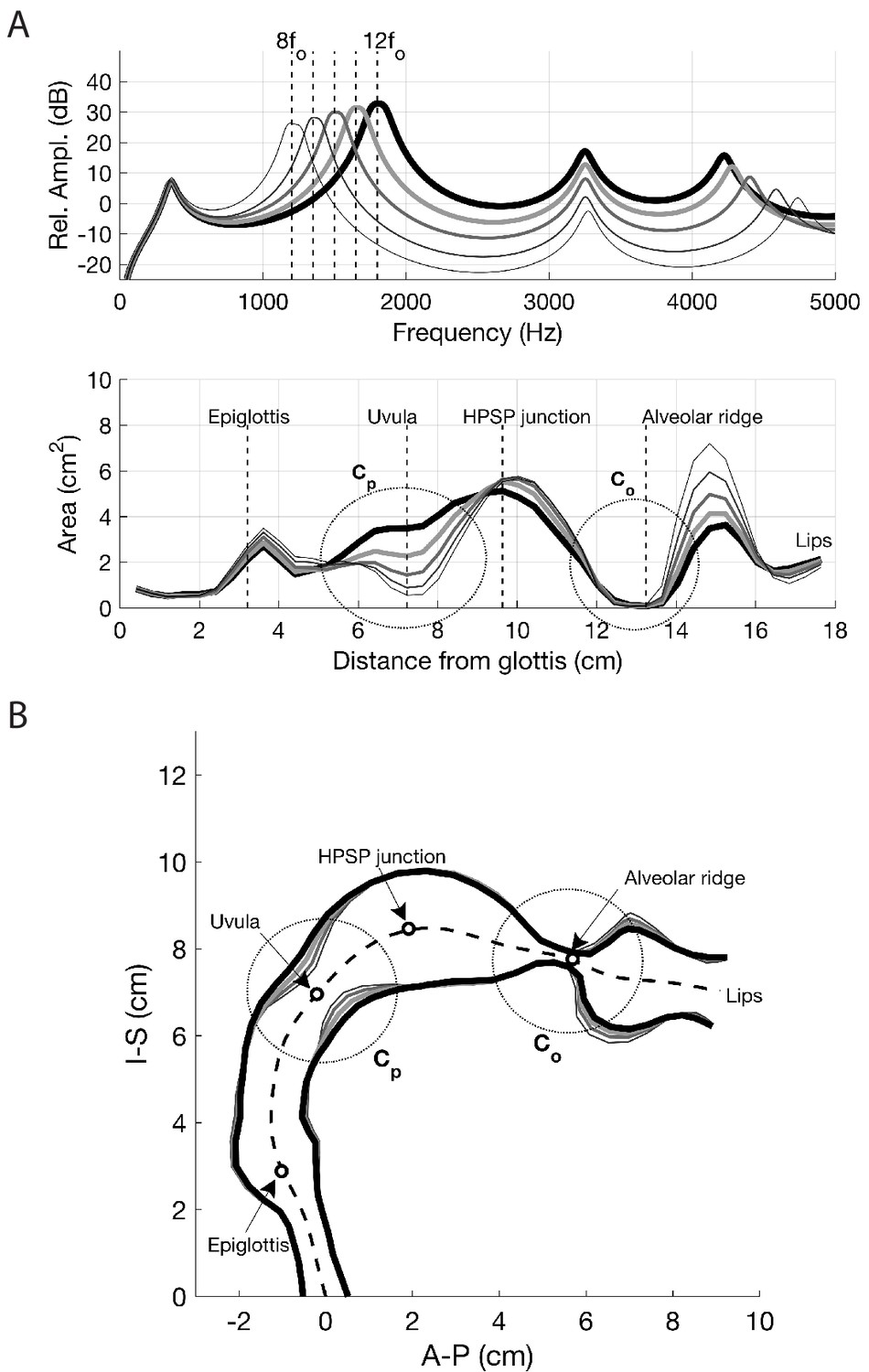
To examine changes in pitch, a particular vocal tract configuration was manually ‘designed (Appendix 1—figure 6) such that it included constrictive and expansive regions at locations similar to those measured from the singer (i.e., Figure 4), but to a less extreme degree. We henceforth denote this area function as A0(x), and it generates a frequency response with widely spaced formant frequencies (F1…5=[529,1544,2438,3094,4236]Hz), essentially a neutral vowel. In many of the audio signals recorded from the singer, the fundamental frequency, fo (i.e., the vibratory frequency of the vocal folds), was typically about 150 Hz. The singer then appeared to enhance one of the harmonics in the approximate range of 8fo…12fo. Taking the 12th harmonic (12×150=1800 Hz) as an example target frequency (dashed line in the frequency response shown in Figure 5c), the area function A0(x) was iteratively perturbed by the acoustic-sensitivity algorithm described in Story (2006) until F2 and F3
converged on 1800 Hz and became a single formant peak in the frequency response. Additional details on the perturbation process leading into Figure 5 are detailed in the Appendix.Appendix 1
This appendix contains supporting information for the document Overtone focusing in biphonic Tuvan throat singing by Bergevin et al. Citations here refer to the bibliography of the main document. First (Methodological considerations), we include several methodological components associated with the quantitative analysis of the waveforms, helping illustrate different approaches towards characterizing the acoustic data and rationale underlying control measures. Second (Additional waveform analyses), we include additional plots to support results and discussion in the main text. For example, different spectrograms are presented, as are analyses for additional waveforms. This section also helps to provide additional context for a second independent focused state. The third section (Additional modeling analysis figures) details theoretical components leading into the results of the computational model and how the MRI data constrain the key parameters, justifying arguments surrounding the notion of formant merging. Fourth (Instability in focused state), some speculative discussion and basic modeling aspects are presented with regard to the notion of instabilities present in the motor control of the focused state. In the fifth section (Additional MRI analysis figures), images stemming from the MRI data are presented. Last, the final three sections detail accessing the acoustic waveforms, MRI data files, and waveform analysis (Matlab-based) software via an online repository.
Methodological considerations
Overtone and formant tracking
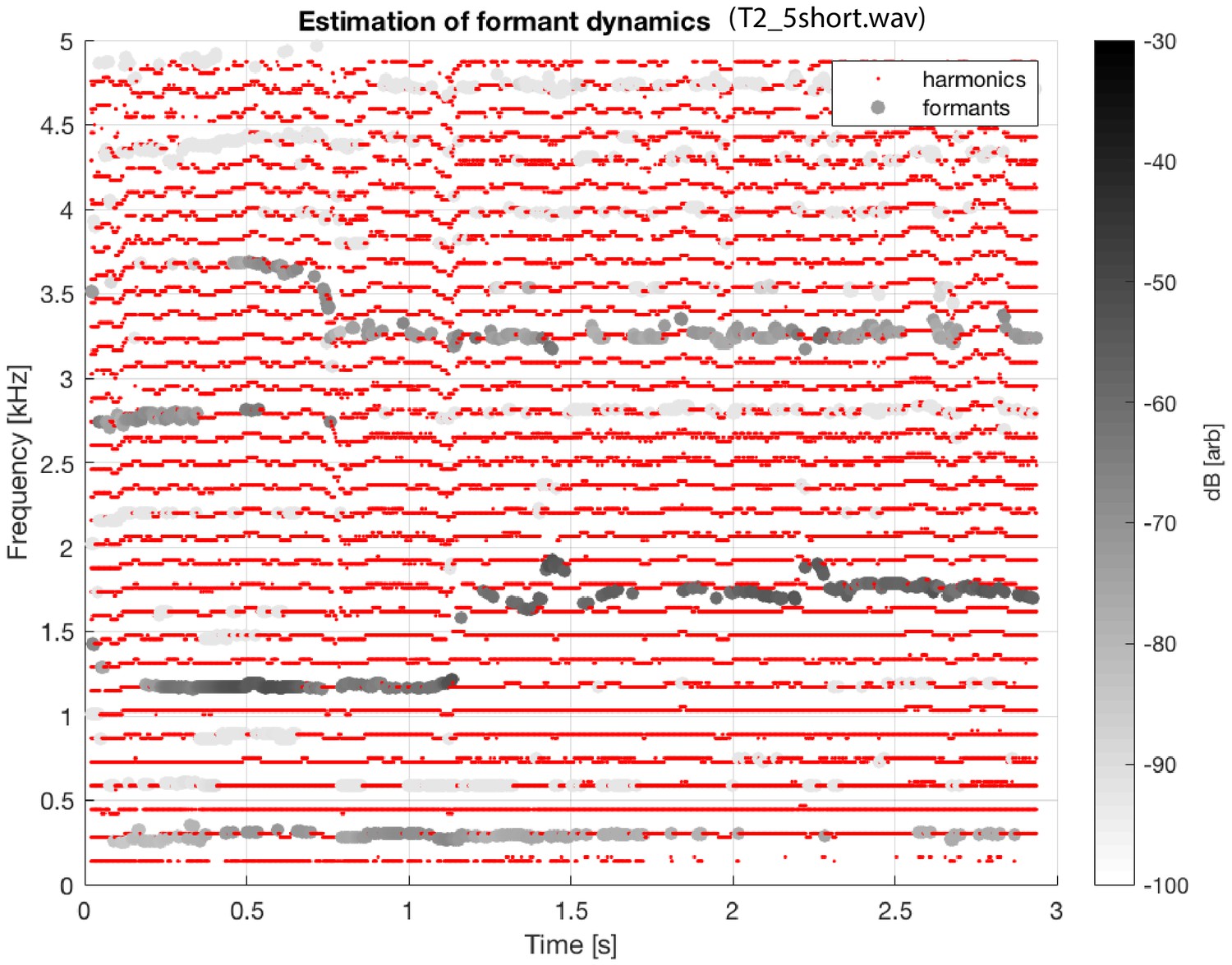
To facilitate quantification of the waveforms, we custom-coded a peak-picking/tracking algorithm to analyze the time-frequency representations produced by the spectrogram. Appendix 1—figure 1 shows an example of the tracking of the overtones (red dots) and formants (grayscale dots; intensity coded by relative magnitude as indicated by the colorbar). This representation provides an alternative view (compared to Figure 1) to help demonstrate that, by and large, the overtone structure is highly consistent throughout, while the formant structure varies significantly across the transition. Appendix 1—figure 1
Same as Figure 1 (middle left panel; subject T2, same sound file as shown in the middle panel of Figure 1), except with overtones and estimated formant structure tracked across time.
Quantifying focused states
Appendix 1—figures 2 and 3 show calculation of the energy ratio eR used as a means to quantify the degree of focus. For Appendix 1—figure 2, the waveforms are the same as those shown in Figure 1 (those with slightly different axis limits). In general, we found that eR(1,2) provided a clear means to distinguish the focused state, as values were close to zero prior to the transition and larger/sustained beyond the transition. Singer T2 was an exception. Appendix 1—figure 3 is for singer T2, using the same file (i.e., the transition point into the focused state at between 6 and 7 s in this figure is the same as that shown in the middle panel of Figure 1), but with an expanded timescale to illustrate the larger eR values prior to the transition. This is due to the relatively large amount of energy present between 2.5–4 kHz. We also explored eR(1,2) values in a wide range of phonetic signals, such as child and adult vocalizations, other singing styles (e.g., opera), non-Tuvan singers (e.g., Westerners) performing ‘overtone singing’, and older recordings of Tuvan singers. In general, it was observed that eR(1,2)
was relatively large and sustained across time for focused overtone song, whereas the value was close to zero and/or highly transient for other vocalizations. Appendix 1—figure 2
Same data/layout as in Figure 1 but now showing eR(1,2)
as defined in the ‘Materials and methods’.
These plots show the energy ratio focused between 1–2 kHz. Vertical red dashed lines indicate approximate time of transition into the focused state. An expanded timescale is also shown for singer T2 … Appendix 1—figure 3
Similar to Figure 2 for singer T2 (middle panel), except an expanded time scale is shown to demonstrate the earlier dynamics as this singer approaches the focused state (see T2_5longer.wav).
Control measurements
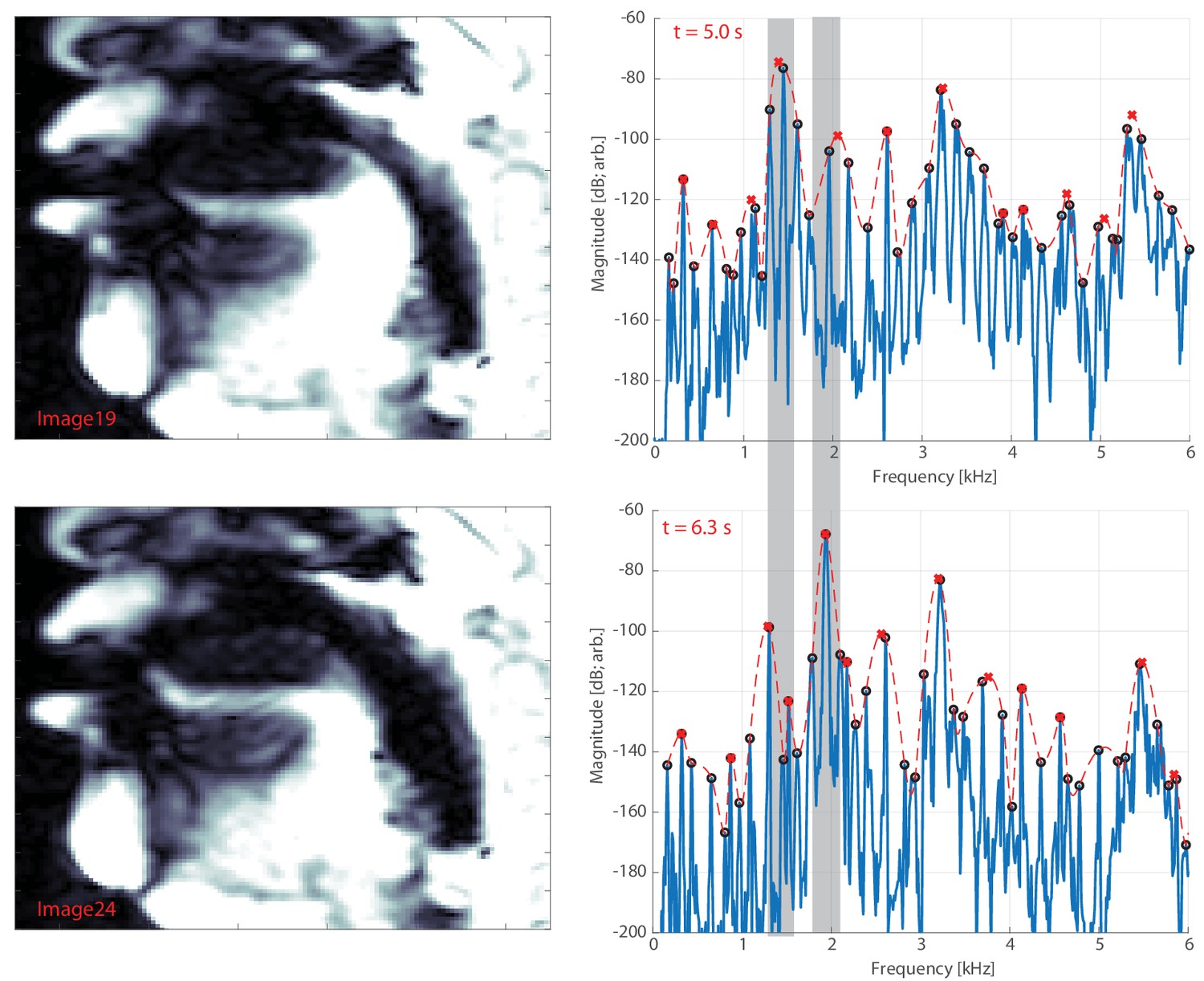
The waveforms from the Tuvan singers provide an intrinsic degree of control (i.e., voicing not in the focused state). Similar to Figure 1, Appendix 1—figure 4 shows the spectra prior to the transition into the focused state. Although relatively narrow harmonics can be observed, they tend to occur below 1 kHz. Such is consistent with our calculations of eR(1,2)
: prior to a transition into a focused state, this value is close to zero. The exception is singer T2, who instead shows a relatively large amount of energy about 1.8–3 kHz that may have some sort of masking effect (see ‘Discussion’ in the main text,and the ‘Pressed transition’ section below). In addition, Tuvan singer T4, who used a non-Sygyt style (Appendix 1—figure 5) , can also effectively be considered a ‘control’. Appendix 1—figure 4
Stemming directly from Figure 1, the right-hand column now shows a spectrum from a time point prior to transition into the focused state (as denoted by the vertical black lines in the left column). The shape of the spectra from Figure 1 is also included for reference.
Appendix 1—figure 5
Spectrogram for singer T4 singing in non-Sygyt style (first song segment of T2_4shortA.wav sound file). For the spectrogram, 4096 point windows were used for the fast Fourier transform (FFT) with 95% fractional overlap and a Hamming window.
Additional waveform analyses
Other spectrograms
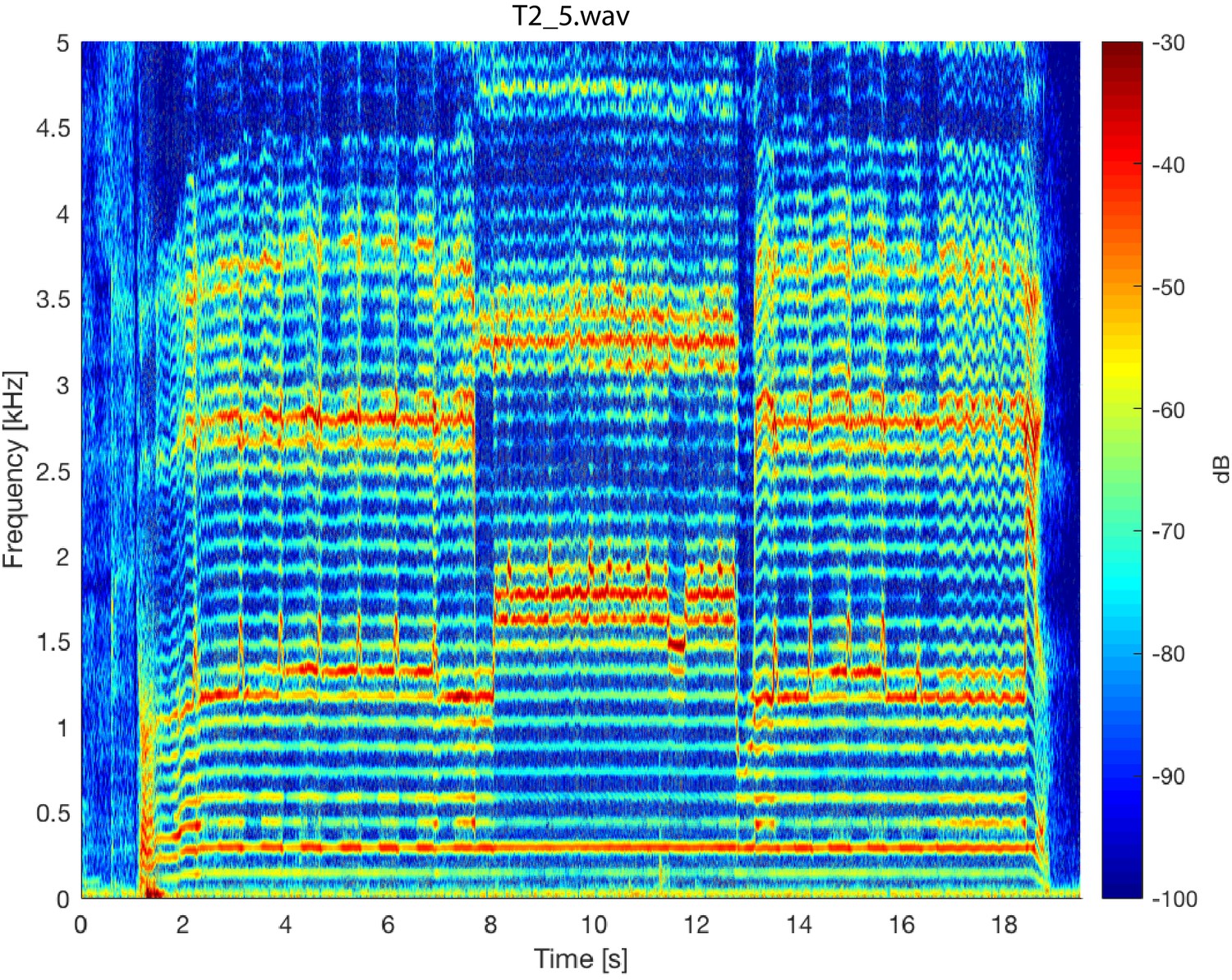
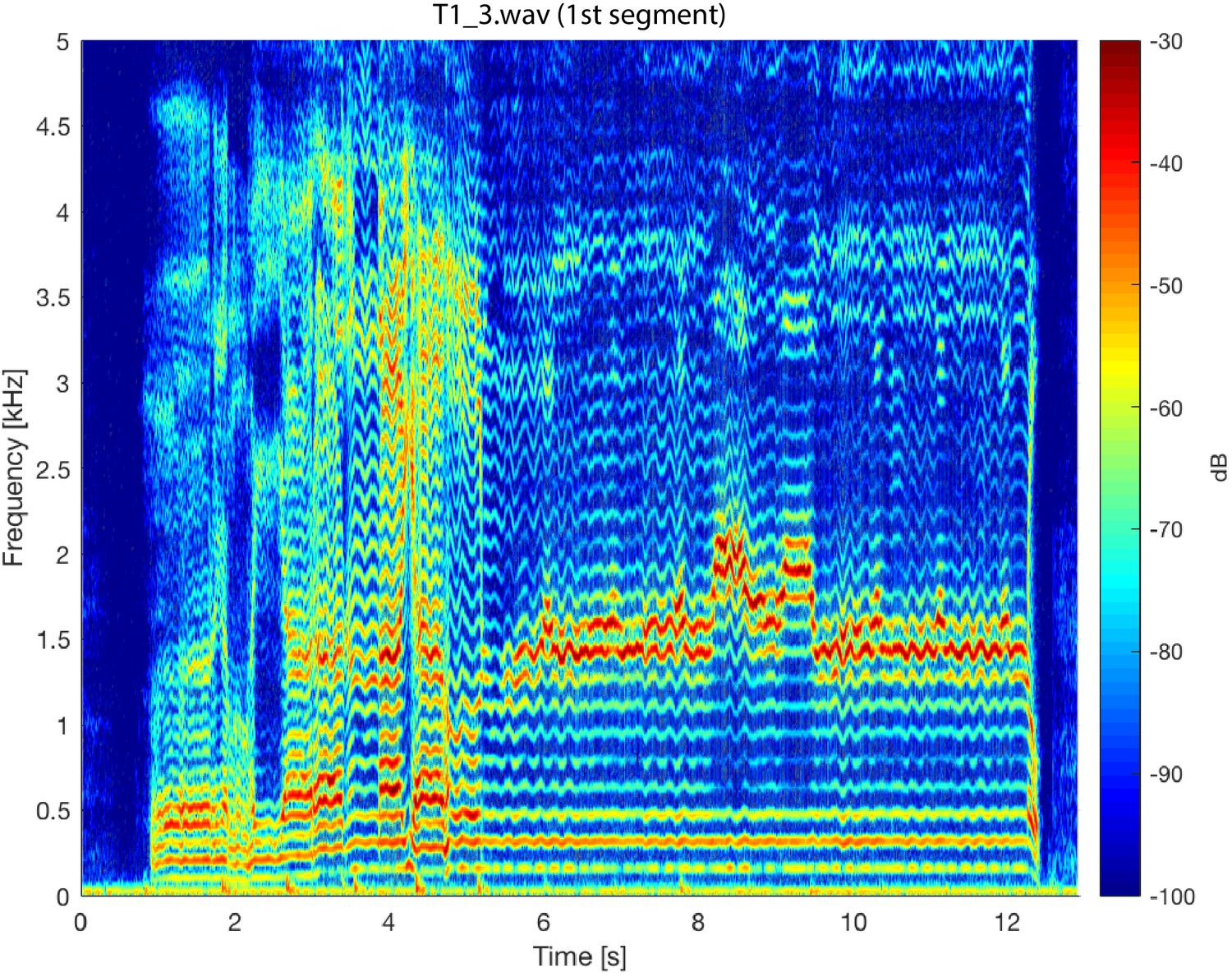
Appendix 1—figure 5 shows spectrogram from singer T4 (T4_shortA.wav) singing in non-Sygyt style. While producing a distinctive sound, note the relative lack of energy above approximately 1 kHz. Appendix 1—figure 6 shows a spectrogram from singer T2 (T2_5.wav) over a longer timescale than that shown in Figure 1. Similarly for Appendix 1—figure 7, but for singer T1. Both of these plots provide a spectral-temporal view of how the singer maintains and modulates the song over the course of a single exhalation. Note both the sudden transitions into different maintained pitches and the briefer transient excursions. Appendix 1—figure 6
Spectrogram of the entire T2_5.wav sound file. The sample rate was 96 kHz. The analysis parameters used were the same as those used for Figure 5.
Appendix 1—figure 7
Spectrogram of the first song segment of the T1_3.wav sound file. The analysis parameters used were the same as those for Figure 5.
Second independent focused state
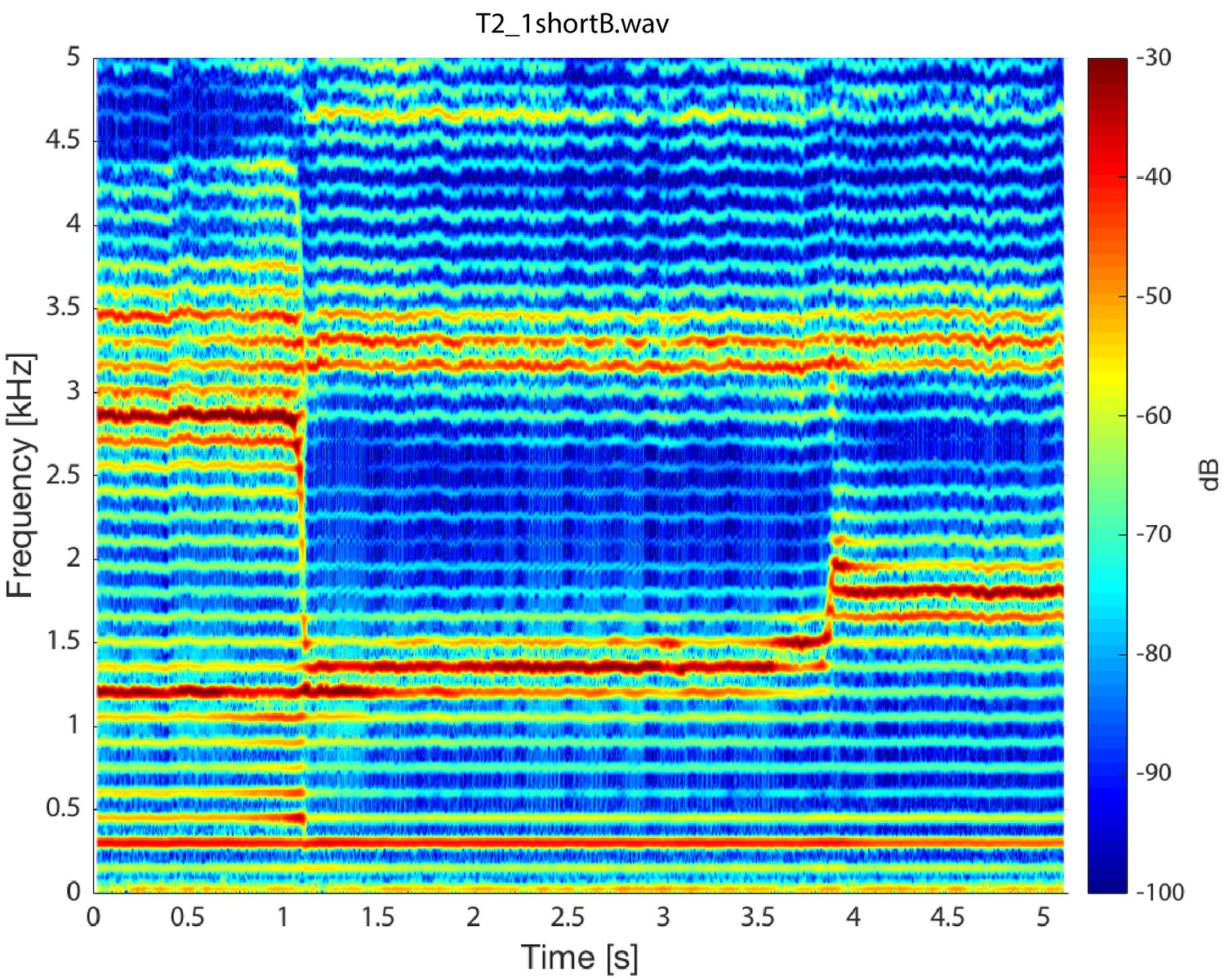
Appendix 1—figure 8 shows another example of a transition in Sygyt-style song for singer T2, clearly showing a second focused state about 3–3.5 kHz. Two aspects merit highlighting. First, the spectral peaks are not harmonically related: at t=4.5
s, the first focused state is at 1.36 kHz and the other at 3.17 kHz (far from to 2.72 kHz as expected). Second, during the singer-induced pitch change at 3.85 s, the two peaks do not move in unison. Although not ruling out correlations between the two focused states, these observations suggest that they are not simply nor strongly related to one another. Appendix 1—figure 8
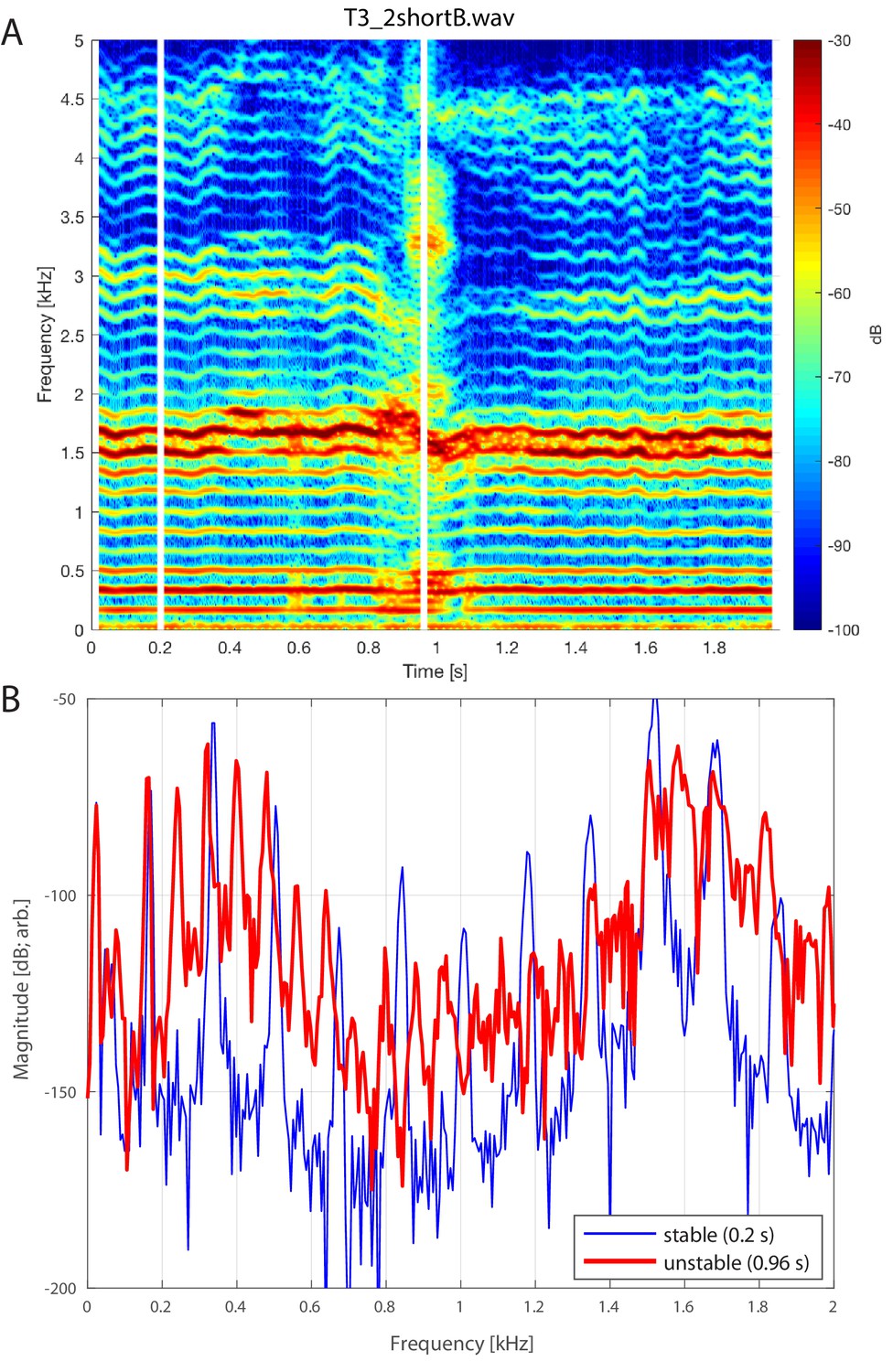
Singer T2’s transition into a focused state. Note that while the first focused state transitions from approximately 1.36 to 1.78 kHz, the second state remains nearly constant, decreasing only slightly from 3.32 to 3.17 kHz (T2_1shortB.wav).
Pressed transition
Appendix 1—figure 9 shows a spectrogram and several spectral slices for the sound file in which the voicing was ‘pressed’ (Adachi and Yamada, 1999; Edmondson and Esling, 2006) prior to the transition into the focused state. That is, prior to the 1.8 s mark, voicing is relatively normal. But after that point (prior to the transition into the focused state around 5.4 s, substantial energy appears between 2–4 kHz along with a degree of vibrato. Note, however, that there is no change to the overall overtone structure (e.g., no emergence of subharmonics). The spectrum at t=4.0s
, prior to the transition, provides a useful comparison back to Levin and Süzükei (2006). Specifically, one particular overtone is singled out and highly focused, yet the broadband cluster of overtones about 2.5–4 kHz effectively mask it. It is not until about the 5.4 s mark, when those higher overtones are also brought into focus, that a salient perception of the Sygyt-style emerges. Appendix 1—figure 9
Spectrogram of singer T2 exhibiting pressed voicing heading into transition to focused state (T2_2short.wav).
Additional modeling analysis figures
The measurement of the cross-distance function (as described in the ‘Materials and methods’), along with calculation of the frequency response from an estimate of the area function, suggested that constrictions of the vocal tract in the region of the uvula and alveolar ridge may play a significant role in controlling the spectral focus generated by the convergence of F2 and F3. Assuming that an overtone singer configures the vocal tract to merge these two formants deliberately such that, together, they enhance the amplitude of a selected harmonic of the voice source, the aim was to investigate how the vocal tract can be systematically shaped with precisely placed constrictions and expansions to both merge F2 and F3
into a focused cluster and move the cluster along the frequency axis to allow for selection of a range of voice harmonics.
Appendix 1—figure 11b shows the same area function as that in Appendix 1—figure 11a (see ‘Materials and methods’) but plotted by extending the equivalent radius of each cross-sectional area, outward and inward, along a line perpendicular to the centerline measured from the singer (see Figure 4A), resulting in an inner and outer outline of the vocal tract shape as indicated by the thick black lines. The measured centerline is also shown in the figure, along with anatomic landmarks. As this does not represent a true midsagittal plane, it will be referred to here as a pseudo-midsagittal plot (Story et al., 2001). Appendix 1—figure 10
Overview of source/filter theory, as advanced by Stevens (2000). The left column shows normal phonation, whereas the right indicates one example of a focused state.
Appendix 1—figure 11
Setup of the baseline vocal tract configuration used in the modeling study. (a) The area function (A0(x)
) is in the lower panel and its frequency response is in the upper panel. (b) The area function from (a) is shown as a pseudo-midsagittal plot (see text).
Appendix 1—figure 12a shows the new area function and frequency response generated by the perturbation process, whereas the pseudo-midsagittal plot is shown in Appendix 1—figure 12b. Relative to the shape of A0(x) (shown as the thin gray line), the primary modification is a severe constriction imposed between 12.5–13.5 cm from the glottis, essentially at the alveolar ridge. Although the line thickness might suggest that the vocal tract is occluded in this region, the minimum cross-sectional area is 0.09 cm2. There is also a more moderate constriction at about 5 cm from the glottis, and a slight expansion between 7–10.5 cm from the glottis. The frequency response in upper panel of Appendix 1—figure 12a demonstrates that the new area function was successful in driving F2 and F3 together to form a single formant peak centered at 1800 Hz, which is at least 15 dB higher in amplitude than any of the other formants. Exactly the same process was used to generate area functions for which F2 and F3 converge on the target harmonic frequencies: 8fo,9fo,10fo,11fo=1200,1350,1500,1650 Hz, respectively. The results, along with those from the previous figure for 12fo, are shown in Appendix 1—figure 13. The collection of frequency responses in the upper panel of Appendix 1—figure 13b shows that F2 and F3 successfully converged to become one formant peak in each of the cases, and their locations on the frequency axis are centered around the specified target frequencies. The corresponding area functions in the lower panel suggests that the constriction between 12.5–13.5 cm from the glottis (alveolar ridge region) is present in roughly the same form for all five cases. By contrast, an increasingly severe constriction must be imposed in the region between 6–8.5 cm from the glottis (uvular region) in order to shift the target frequency (i.e., the frequency at which F2 and F3 converge) downward through progression of specified harmonics. Coincident with this constriction is a progressively larger expansion between 14–15.5 cm from the glottis, which probably assists in positioning the focal regions of F2 and F3 downward. It can also be noted that the area function that generates a focus at 8fo
(1200 Hz; thinnest line) is most similar to the one generated from the cross-distance measurements (i.e., Figure 4c). In both, there are constrictions located at about 7.5 cm and 13 cm from the glottis; the expansions in the lower pharynx and oral cavity are also quite similar. The main difference is the greater expansion of the region between 8–13 cm from the glottis in the acoustically derived area function.
On the basis of the results, a mechanism for controlling the enhancement of voice harmonics can be proposed: the degree of constriction near the alveolar ridge in the oral cavity (labeled Co in Figure 5 of the main text) controls the proximity of F2 and F3 to each other, whereas the degree of constriction near the uvula in the upper pharynx, Cp, controls the frequency at which F2 and F3 converge (the expansion anterior to Co may also contribute). Thus, an overtone singer could potentially ‘play’ (i.e., select) various harmonics of the voice source by first generating a tight constriction in the oral cavity near the alveolar ridge to generate the focus of F2 and F3
, and then modulating the degree of constriction in the uvular region of the upper pharynx to position the focus on a selected harmonic.
This proposed mechanism of controlling the spectral focus is supported by observation of vocal tract changes based on dynamic MRI data sets. Using this approach, midsagittal movies of the Tuvan singer were acquired in which each image represented approximately 275 ms. Shown in Figure 5 is a comparison of vocal tract configurations derived with the acoustic-sensitivity algorithm (middle panels) to image frames from an MRI-based movie (upper panels) associated with the points in time indicated by the vertical lines superimposed across the waveform and spectrogram in the lower part of the figure. The image frames were chosen such that they appeared to be representative of the singer placing the spectral focus at 8fo (left) and 12fo (right), respectively, based on the evidence available in the spectrogram. The model-based vocal tract shape in the upper left panel, derived for a spectral focus of 8fo (1200 Hz), exhibits a fairly severe constriction in the uvular region, similar to the constrictive effect that can be seen in the corresponding image frame (middle left). Likewise, the vocal tract shape derived for a spectral focus of 12fo
(1800 Hz) (upper right) and the image frame just below it both demonstrate an absence of a uvular constriction. Thus, the model-based approach generated vocal tract shapes that appear to possess characteristics similar to those produced by the singer, and provides support for the proposed mechanism of spectral focus control. Appendix 1—figure 12
Results of perturbing the baseline area function A0(x)
so that F2
and F3
converge on 1800 Hz.
(a) Perturbed area function (thick black line) and the corresponding frequency response; for comparison, the baseline area function is also shown (thin gray line). The frequency response shows the … Appendix 1—figure 13
Results of perturbing the baseline area function A0(x)
so that F2
and F3
converge on 1200, 1350, 1500, 1650, and 1800 Hz.
(A) Perturbed area functions and corresponding frequency responses; line thicknesses and gray scale are matched in the upper and lower panels. (B) Pseudo-midsagittal plot of the perturbed area …
Second focused state
Given that singer T2 was the subject for the MRI scans and uniquely exhibited a second focused state (e.g., Appendix 1—figure 8), the model was also utilized to explore how multiple states could be achieved. Two possibilities appear to be the sharpening of formant F4 alone, or the merging of F4 and F5 (Appendix 1—figure 14). However, it is unclear how reasonable those vocal tract configurations may be and further study is required. Appendix 1—figure 14
Similar to Figure 5, but additional manipulations were considered to create a second focused state by merging F4 and F5, as exhibited by singer T2 (see middle row in Figure 1). In addition, the spectrogram shown here is from the model (not the singer’s audio). See also Appendix 1—figure 20 for connections back to dynamic MRI data.
Animations and synthesized song
Animations and audio clips demonstrating various quantitative aspects of the model are included in the data files posted to datadryad.org. Specifically they are:
o Animation (no sound) of vocal tract changes during transition into focused state and subsequent pitch changes – Medley 0 to5 1 cluster.mp4Audioclipof simulatedsong
o Audio clip of simulated song – Medley 0 to5 1 cluster s im.wav
Instability in focused state
Appendix 1—figure 15 and Appendix 1—figure 16 show that brief transient instabilities in the focused state can and do regularly occur. Specifically, it can be observed that there are brief transient lapses while the singer is maintaining the focused overtone condition, thereby providing insight into how focus is actively maintained. One possible explanation is control by virtue of biomechanical feedback, where the focused state can effectively be considered to be an unstable equilibrium point, akin to balancing a ruler vertically on the palm of your hand. An alternative consideration might be that singers learn to create additional quasi-stable equilibrium points (e.g., Appendix 1—figure 17). The sudden transitions observed (Figure 1) could then be likened to two-person cheerleading moves such as a ‘cupie’, where one person standing on the ground suddenly throws another up vertically and has them balancing atop their shoulders or upward-stretched hands. A simple proposed model for the transition into the focused state is shown in Appendix 1—figure 17. There, a stable configuration of the vocal tract would be the low point (pink ball). Learning to achieve a focused state would give rise to additional stable equilibria (red ball), which may be more difficult to maintain. Considerations along these lines, combined with a model for biomechanical control (e.g., Sanguineti et al., 1998), can lead to testable predictions specific to when a highly experienced singer is maintaining balance about the transition point into/out of a focused state (e.g., T2_4.wav audio file). Appendix 1—figure 15
Brief instability in the focused state. (A) Spectrogram of singer T3 during period during which the focused state briefly falters (T3_2shortB.wav, extracted from around the 33 s mark of T3_2.wav). (B) Spectral slices taken at two …
Appendix 1—figure 16
Spectrogram of singer T2 (T2_1shortA.wav) about a transition into a focused state. Note that there is a slight instability around 4.5 s.
Appendix 1—figure 17
Schematic illustrating a simple possible mechanical analogy (ball confined to a potential well) for the transition into a focused state.
Additional MRI analysis figures
Volumetric data
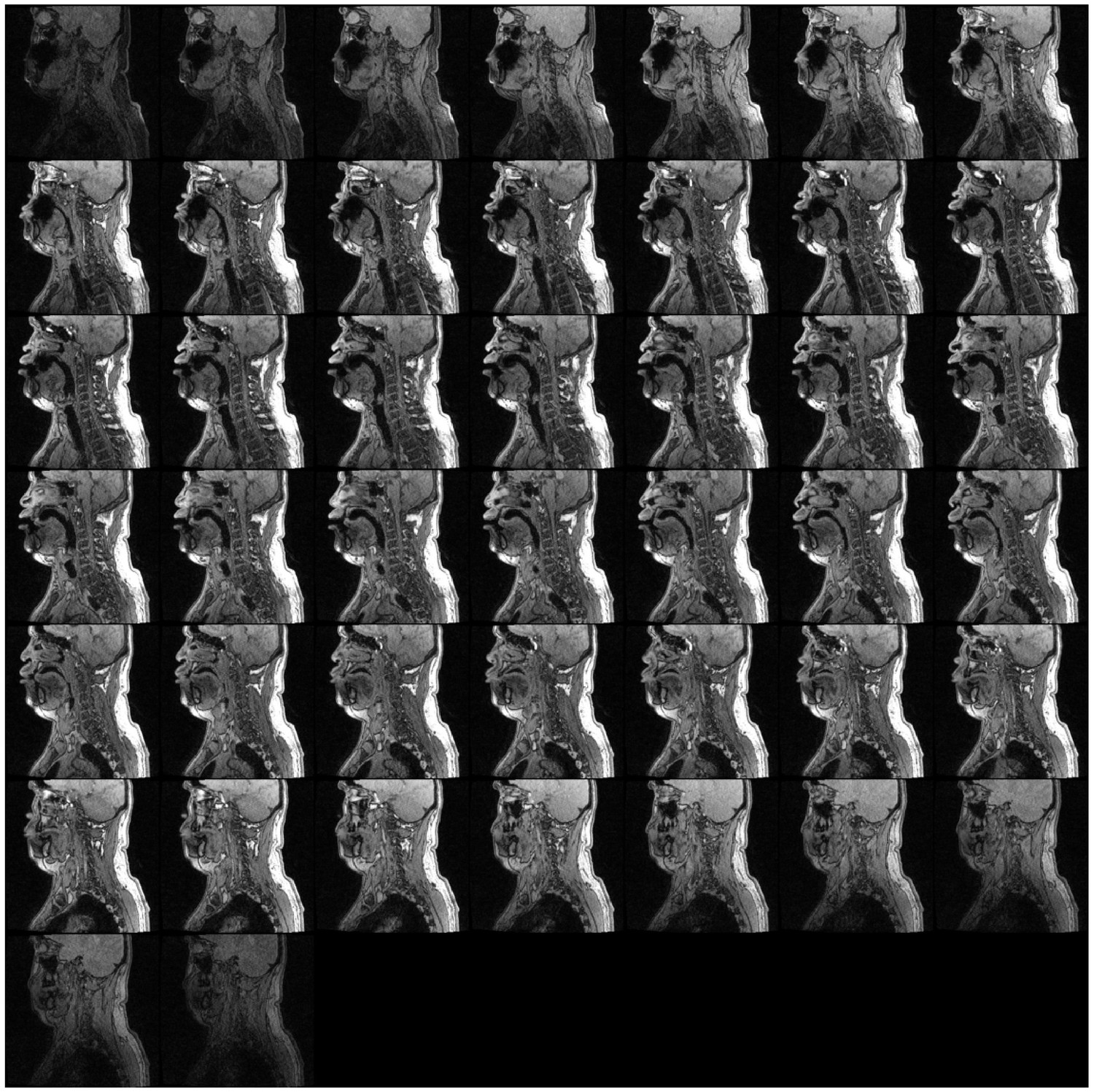
An example of the volumetric data (arranged as tiled midsagittal slices) is shown in Appendix 1—figure 18. Note that the NMR artifact resulting from the presence of a dental post is apparently lateralized to one side.
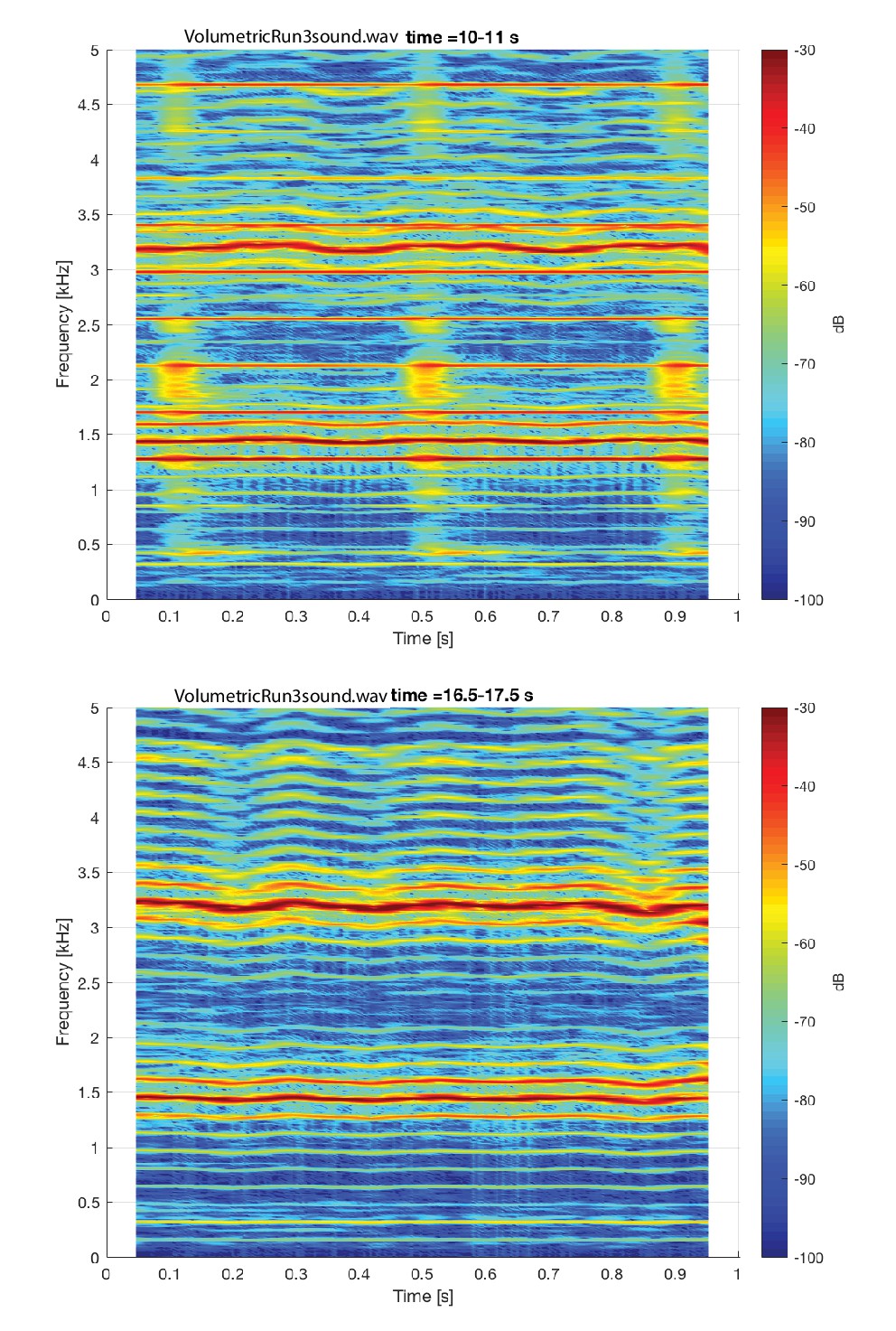
Appendix 1—figure 19 shows a spectrogram of audio segment (extracted from Run3Vsound.wav) associated with the volumetric scan shown in Appendix 1—figure 18. Segments both with and without the scanner noise are shown.
Vocal tract shape and associated spectrograms
Examples of the vocal tract taken during the dynamic MRI runs (i.e., midsagittal only) are shown for very different representative time points in Appendix 1—figure 20. Appendix 1—figure 18
Mosaic of single slices from the volumetric MRI scan (Run3) of subject T2 during focused overtone state. Spectrogram of corresponding audio shown in Appendix 1—figure 19.
Appendix 1—figure 19
Spectrogram of steady-state overtone voicing assocaited with the volumetric scan shown in Appendix 1—figure 18. Two different one-second segments are shown: the top segment shows images there were made during the scan (and thus includes acoustic noise from the scanner during image acquisition), while the botto…
Appendix 1—figure 20
Representative movie frames and their corresponding spectra for singer T2, as input into modeling parameters (e.g., Figure 5). The corresponding Appendix data files are DynamicRun2S.mov (MRI images) and DynamicRun2sound.wav (spectra; see also DynamicRun2SGrid.pdf). The top row shows a ‘low pitch’ (first) focused state at …
Data
All data relevant to the study have been placed in the online repository – https://datadryad.org/stash (Bergevin, 2020). Below is a list of the data placed there, along with a brief description (see ‘Materials and methods’ section for additional details).
Acoustic data
All waveforms were obtained at a sample rate of 96 kHz and a bit-depth of 24 bits.
T1_1.wav
T1_2.wav
T1_3.wav
T1_3short.wav
T2_1.wav
T2_1shortA.wav
T2_1shortB.wav
T2_1shortC.wav
T2_2.wav
T2_2short.wav
T2_3.wav
T2_4.wav
T2_5.wav
T2_5longer.wav
T2_5short.wav
T3_2.wav
T3_2shortA.wav
T3_2shortB.wav
T4_1.wav
T4_1shortA.wav
MRI data
* Images Images were only obtained from singer T2. Note that all image data are saved as DICOM files (i.e., .dcm) :
Volumetric Run1
Volumetric Run2
Volumetric Run3
Dynamic midsagittal Run1
Dynamic midsagittal Run2
Dynamic midsagittal Run3
* Audio recordings acquired during MRI acquisition (see ‘Materials and methods’).
Vol. Run1 audio
Vol. Run2 audio
Vol. Run3 audio
Dyn. Run1 audio
Dyn. Run2 audio
Dyn. Run3 audio
* MRI Midsagittal movies with sound were also created by animating the frames in Matlab and syncing the recorded audio via Wondershare Filmora. They are saved as .mov files (Apple QuickTime Movie files):
Dyn. Run1 video
Dyn. Run2 video
Dyn. Run3 video
To facilitate connecting movie frames back to the associated sound produced by singer T2 at that moment, the movies include frame numbers. Those have been labeled on the corresponding time location in the spectrograms (see red labels at top):
Dyn. Run1 spectrogram
Dyn. Run2 spectrogram
Dyn. Run3 spectrogram
* Segmented volumetric data files (like those shown in Figure 3), data saved as STL files (i.e., .stl):
Segmented data (T2)
Software and synthesized song
Simulations and waveform analysis were implemented in Matlab. The TubeTalker software is provided ‘as is’:
Code to analyze general aspects of the waveforms (e.g., Figure 1 spectrograms)
Timothy D Griffiths Reviewing Editor; University of Newcastle, United Kingdom
Barbara G Shinn-Cunningham Senior Editor; Carnegie Mellon University, United States
In the interests of transparency, eLife publishes the most substantive revision requests and the accompanying author responses.
Acceptance summary:
Tuvan throat singing, in which people are able to simultaneously produce and independently control two different distinct pitches using the human vocal apparatus, has fascinated hearing and speech researchers for decades. This careful study examines the acoustics of the produced sound and offers new insights into why the produced sound results in two distinct, separately controllable pitches.
Decision letter after peer review:
Thank you for submitting your article “Overtone focusing in biphonic Tuvan throat singing” for consideration by eLife. Your article has been reviewed by two peer reviewers, one of whom is a member of our Board of Reviewing Editors, and the evaluation has been overseen by Barbara Shinn-Cunningham as the Senior Editor. The reviewers have opted to remain anonymous.
The reviewers have discussed the reviews with one another, and the Reviewing Editor has drafted this decision to help you prepare a revised submission.
Summary
We enjoyed this work addressing mechanisms by which throat singers produce dual pitches that assesses the mechanism for this in terms of the ways in which the vocal tract is precisely controlled based on MRI videos. The work mentions other biological examples of dual fundamentals in songbirds for the broad eLife audience. One of the issues that came up in discussion was the control for normal vocalisations without biphonation, but I think the authors make a reasonable case that the singers act as their own controls. Basically, the work shows that the dual pitch mechanism is associated with changes in the vocal tract morphology based on two constrictions that merge second and third formants and is associated with what they call a ‘focussed state’ in which the harmonics at 1.5kHz to 2kHz are accentuated. The idea as I understand it is that this accentuates a single harmonic of the fundamental glottal pulse rate so that a new high frequency component of Khoomei emerges that is in effect perceptually ‘released’ from the harmonic series to allow the emergence of the high pitched whistling part of the song.
Major comments
1) From first principles, dual pitch singing could be achieved by a different type of glottal pulse generation in the larynx so that two vibration modes were present (as in avian syrinx). This is not the mechanism suggested here, and it is hard to see how the anatomy and physiology of the human larynx might allow this, but this has not been directly examined in the MRI work. The authors carried out a careful acoustic analysis which shows only one harmonic series before and after transitions to throat singling (without shifting), which I think is adequate. But they might comment on the other possible mechanism for biological readers, if only to dismiss it.
2) Both reviewers thought the discussion of the basis for the perceived dual pitch was not clear. The authors discuss differences in cochlear mechanisms between low frequency regions and high frequency regions. More effort could be made to explain how the dual pitch, which is attributed to a type of spectral emphasis, can be reconciled with current models of pitch perception. The fundamental for the singers assessed was ~150Hz so that the >1.5 kHz region will be unresolved (H10 and above). The greatest contribution to the salience of the low pitch will be the resolved harmonics at frequencies below the focus region, which are well represented. The high-frequency harmonics will usually contribute (weakly) to the low pitch based on the temporal firing patterns due to merged harmonics in frequency bands. The authors appear to be arguing that a different spectral pitch emerges in the high frequency focussed region, distinct from that associated with the lower harmonics.
3) The argument about decreased phase locking at high frequency was not convincing: this occurs in a much higher frequency region that the focussed region. The argument that the high pitch was not easily explained by a non-linear distortion was convincing.
4) In conclusion, we thought the work nicely shows the changes in vocal tract morphology and associated spectrum as an explanation for the dual pitch, but more teasing out of mechanism for the dual pitch perception is required in a way that might be accessible to readers.
[Editors’ note: further revisions were suggested prior to acceptance, as described below.]
Thank you for submitting your article “Overtone focusing in biphonic Tuvan throat singing” for consideration by eLife. Your article has been reviewed by a member of our Board of Reviewing Editors and Barbara Shinn-Cunningham as the Senior Editor.
We are afraid we are still not satisfied with the discussion of the basis for the dual pitch at the end of the Discussion. The authors have demonstrated a region of spectral focus as a proposed mechanism for the new pitch. But we still do not understand why the focussed overtones produce a different pitch. They are still harmonics of the same fundamental and interactions between them in this unresolved region would be expected to produce beating at the same frequency as the fundamental, in the absence of non-linear mechanisms. We also do not understand what the additional relevance of a decrease in phase locking in this region would be that the authors highlight. Are the authors claiming that the focused region produces spectral excitation in a region without the usual coding of beating between harmonics (because of decreased phase locking) and that this is the cause of the new pitch? If so an explicit suggestion along those lines might help readers who are familiar with conventional pitch models.
eLife does not usually encourage multiple rounds of revision but this is a critical point in the interpretation of an interesting study, and I would encourage a revision with a much shorter final section of Discussion that explains a clear hypothesis related to the cause of the new pitch.https://doi.org/10.7554/eLife.50476.sa1Author response
Major comments
1) From first principles, dual pitch singing could be achieved by a different type of glottal pulse generation in the larynx so that two vibration modes were present (as in avian syrinx). This is not the mechanism suggested here, and it is hard to see how the anatomy and physiology of the human larynx might allow this, but this has not been directly examined in the MRI work. The authors carried out a careful acoustic analysis which shows only one harmonic series before and after transitions to throat singling (without shifting), which I think is adequate. But they might comment on the other possible mechanism for biological readers, if only to dismiss it.
We attempted to further clarify the point (that we saw no evidence for a nonlinear source mechanism) and added an additional line of text as per the suggestion.
2) Both reviewers thought the discussion of the basis for the perceived dual pitch was not clear. The authors discuss differences in cochlear mechanisms between low frequency regions and high frequency regions. More effort could be made to explain how the dual pitch, which is attributed to a type of spectral emphasis, can be reconciled with current models of pitch perception. The fundamental for the singers assessed was ~150Hz so that the >1.5 kHz region will be unresolved (H10 and above). The greatest contribution to the salience of the low pitch will be the resolved harmonics at frequencies below the focus region, which are well represented. The high-frequency harmonics will usually contribute (weakly) to the low pitch based on the temporal firing patterns due to merged harmonics in frequency bands. The authors appear to be arguing that a different spectral pitch emerges in the high frequency focussed region, distinct from that associated with the lower harmonics.
This criticism was given particularly serious thought and consideration. As a result, we totally rewrote this section to make the proposed ideas clearer, as well as accessible to a broad readership. We tried to find a better balance between issues/questions related to pitch coding and those to cochlear mechanics.
3) The argument about decreased phase locking at high frequency was not convincing: this occurs in a much higher frequency region that the focussed region. The argument that the high pitch was not easily explained by a non-linear distortion was convincing.
As alluded to in the comments above, we clarified the nature of the argument (re phase locking) by expanding upon the discussion of pitch coding. While a reasonable degree of phase locking would still be expected around the 1.5-2 kHz region, this is also where temporal coding starts to fall off dramatically (e.g., Verschooten et al., 2018, PLoS Biol.). That facet, that in the 1-2 kHz region of the human cochlea the fidelity of timing information changes, is what is relevant to the narrative thread here.
4) In conclusion, we thought the work nicely shows the changes in vocal tract morphology and associated spectrum as an explanation for the dual pitch, but more teasing out of mechanism for the dual pitch perception is required in a way that might be accessible to readers.
See comments above.
[Editors’ note: further revisions were suggested prior to acceptance, as described below.]
[…]
eLife does not usually encourage multiple rounds of revision but this is a critical point in the interpretation of an interesting study, and I would encourage a revision with a much shorter final section of Discussion that explains a clear hypothesis related to the cause of the new pitch.
As we would like to see this work published with eLife, we have drastically truncated the highlighted section to create “a much shorter final section” as suggested. Given our lack of expertise in pitch perception, coupled with our appreciation for the comments raised, we instead (succinctly) reframed through the lens of looking ahead at future work. Specifically, we include only what we think are some quite interesting and provocative parallels we have observed between Sygyt song and cochlear mechanics. We believe that providing this as a summary to the narrative will help stimulate crosstalk between emerging viewpoints in cochlear mechanics and central processing (e.g., pitch perception).
As such, hopefully we have a more streamlined “story” that will be sufficient for
publication. We believe the rest of the work paints a clear picture as to how the
Natural Sciences and Engineering Research Council of Canada (RGPIN-430761-2013)
Christopher Bergevin
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
A heartfelt thank you to Huun Huur Tu, without whom this study would not have been possible. Input/suggestions from Ralf Schlueter, Greg Huber, Dorothea Kolossa, Chris Rozell, Tuomas Virtanen, and the reviewers are gratefully acknowledged. Support from York University, the Fields Institute for Research in Mathematical Sciences, and the Kavli Institute of Theoretical Physics is also gratefully acknowledged. CB was supported by the Natural Sciences and Engineering Research Council of Canada (NSERC) Grant RGPIN-430761–2013. The identification of specific products or scientific instrumentation does not constitute endorsement or implied endorsement on the part of the author, Department of Defense, or any component agency. The views expressed in this article are those of the authors and do not reflect the official policy of the Department of Army/Navy/Air Force, the Department of Defense, or the U.S. Government.
Ethics
Human subjects: Data were collected with approval of the York University Institutional Review Board (IRB protocol to Prof Jennifer Steeves) This study was approved by the Human Participants Review Board of the Office of Research Ethics at York University (certificate #2017-132) and adhered to the tenets of the Declaration of Helsinki. All participants gave informed written consent and consent to publish prior to their inclusion in the study.
Senior Editor
Barbara G Shinn-Cunningham, Carnegie Mellon University, United States
Reviewing Editor
Timothy D Griffiths, University of Newcastle, United Kingdom
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.Metrics
Le chant diphonique ou comment chanter seul à deux voix
Le chant diphonique est une technique qui permet à un chanteur de produire en même temps deux notes de fréquences différentes : une spécificité vocale pratiquée depuis très longtemps, dans de nombreuses régions du monde, dont le Tibet.
Une superposition de deux voix
L’interprète d’un chant diphonique émet simultanément un bourdon et des sons harmoniques. Le premier, dit « bourdon » ou « son fondamental », correspond à la voix normale. Il est maintenu avec la même fréquence, la même puissance, sur la même inspiration et permet à la mélodie de venir sur superposer. Il sert de base au second son : le son dit « harmonique » variant dans les aigus et produisant l’effet mélodique.
Cette production simultanée de deux voix nécessite un larynx puissant comme peut l’être celui d’un ventriloque et bien sûr, une parfaite maîtrise du souffle. Le chant diphonique fait appel à différentes techniques. L’une s’appuie sur la voix de gorge obtenue en contractant les muscles du cou. Ce son est bien plus grave que celui mettant en jeu seulement les cordes vocales.
L’autre repose sur une modulation de la cavité phonatoire. Grâce à la mobilité de la mâchoire, l’ouverture de la bouche, la position des lèvres et de la langue faisant pression sur le palais, le chanteur peut émettre des harmoniques venant se superposer sur le bourdon. La langue peut, par exemple, servir à diviser la cavité buccale en deux résonateurs de plus petit volume, donc de fréquence plus élevée.
Les chants traditionnels des moines tibétains
Les chants diphoniques les plus connus sont certainement ceux des moines tibétains, des monastères Gyütö et Gyüme. Mais on retrouve cette singularité vocale dans d’autres régions d’Asie : chez les Mongols, les Touvains (originaires de la Touva, en Sibérie orientale), les Bachkirs (un peuple turc originaire de Russie et d’Ouzbékistan), les Rajasthanais de l’Inde, mais également chez les Xhosas d’Afrique du Sud.
BONNE NOUVELLE : le mot DIPHONIQUE est accepté dans le dictionnaire LE PETIT ROBERT , version 2020. Après plusieurs années de demande auprès de la direction du dictionnaire LE PETIT ROBERT , j’ai finalement réussi à faire accepter le mot DIPHONIQUE dans le dictionnaire LE PETIT ROBERT en 2020
and Seiji Niimi∗4 ∗1 NTT Communication Science Laboratories, ∗2 The University of Tokyo, ∗3 National Rehabilitation Center for the Disabled, ∗4 International University of Health and Welfare
KEN-ICHI SAKAKIBARA
Introduction
Throat singing is a traditional singing style of people who live around the Altai mountains. Kh¨ o¨ omei in Tyva and Kh¨ o¨ omij in Mongolia are representative styles of throat singing. Throat singing is sometimes called biphonic singing, multiphonic singing, overtone singing, or harmonic singing because two or more distinct pitches (musical lines) are produced simultaneously in one tone. One is a low sustained fundamental pitch, called a drone, and the second one is a whistle-like harmonic that resonates high (in the range from 1 kHz to 3 kHz) above the drone. Many variations of singing styles in throat singing are classified according to singers and regions. However, it is possible to objectively classify these variations in the terms of a source-filter model in speech production. The laryngeal voices of throat singing can be classified into (i) a pressed voice and (ii) a kargyraa voice based on listener’s impression, acoustical characteristics, and the singer’s personal observation on voice production. The pressed voice is the basic laryngeal voice in throat singing and used as drone. The kargyraa voice is a very low pitched voice that ranges out of the modal register. The production of the high pitched overtone is mainly due to the pipe resonance of the cavity from the larynx to the point of articulation in the vocal tract [1]. In Tyvan kh¨ o¨ omei, sygit is a style where singers articulate by touching the tongue to the palate and kh¨ o¨ omei is one where they articulate by pursing the lips. We have also physiologically observed two different laryngeal voices and estimated the patterns of the vocal fold and false vocal fold vibrations [6]. We have simulated the vibration patterns by a physical modeling of the larynx: 2 × 2-mass model. Based on the physiological observations and the simulation, we propose a new laryngeal voice model and synthesis system for throat singing
Università di Padova Dipartimento di Storia delle Arti Visive e della Musica ceolin.elena@libero.it
ISTC (Istituto di Scienze e Tecnologie della Cognizione), CNR, Padova tisato@pd.istc.cnr.it
Università di Padova Dipartimento di Storia delle Arti Visive e della Musica laura.zattra@unipd.it
ABSTRACT Demetrio Stratos (1945-1979) was a singer known for his creative use of vocal techniques such as diplophony, bitonality and diphony (overtone singing). His need to know the scientific explanation for such vocal behaviors, drove him to visit the ISTC in Padova (Institute of Cognitive Sciences and Technologies) in the late Seventies. ISTC technical resources and the collaboration with Franco Ferrero and Lucio Croatto (phonetics and phoniatric experts), allowed him to analyze his own phonoarticulatory system and the effects he was able to produce. This paper presents the results of a broad historical survey of Stratos’ research at the ISTC. The historic investigation is made possible by textual criticism and interpretation based on different sources, digital and audio sources, sketches, various bibliographical references (published or unpublished) and oral communications. Sonograms of Stratos’ exercises (made at the time and recently redone) show that various abilities existed side by side in the same performer, which is rare to find. This marks his uniqueness in the avant-gard and popular music scene of the time. The ultimate aim of this study was to produce a digital archive for the preservation and conservation of the sources related to this period.
Tran Quang Hai : Metodo per Imparare il Canto Armonico di Stile KHOOMEI
Posted on by haidiphonieStandardMetodo per Imparare il Canto Armonico di Stile KHOOMEI Tran Quang Hai (Francia) Negli ultimi 40 anni si sono prodotte un numero considerevole di ricerche riguardo questo peculiare fenomeno vocale, in particolare sulle modalità con le quali esso è praticato in Mongolia e a Tuva. In mongolo e tuvano la parola KHOOMEI significa faringe, gola e KHOOMEILAKH è la tecnica di produrre armonici vocali. Questa tecnica piuttosto insolita, che porta la voce umana ai suoi limiti, comporta la produzione simultanea di due suoni: un suono grave o fondamentale che è ricco di armonici e la reminiscenza dello Jew’s harp[1] (motivo per cui questa tecnica è anche chiamata “ Jew’s harp voice”). Secondo i cantanti della Mongolia questa tecnica è molto faticosa. L’esecutore deve tendere i muscoli e gonfiare le guance. Variando la pressione dell’aria attraverso le corde vocali, il volume del cavo orale e la posizione della lingua, vengono ottenuti suoni diversi. In questo modo, armonici di diverse frequenze vengono prodotti formando melodie. La fondamentale viene prodotta nel retro della gola, passando attraverso il cavo orale e attraverso l’eccitazione delle labbra leggermente divise e in misura minore attraverso il naso. La ricerca può essere eseguita in molti modi: dai sistemi di osservazione degli esecutori nativi dopo una o più visite nei paesi che interessano, o attraverso una pratica strumentale e un addestramento vocale che mirano ad una migliore comprensione della struttura musicale assunta dalla popolazione studiata. La mia ricerca non appartiene a una di queste due categorie in quanto non sono stato in Mongolia e non ho imparato lo stile KHOOMEI (canto armonico) da un insegnante Mongolo. Quello che ora vado descrivendo è il risultato dei miei propri esperimenti che abiliteranno chiunque a produrre due note simultaneamente in maniera simile allo stile Mongolo e Tuvano di canto armonico. ——————————————————————————– DEFINIZIONE La maniera con la quale viene tradotta la parola Mongola o Tuvana non è uniforme: HO-MI, HÖ-MI (Vargyas, 1968), KHOMEI, KHÖÖMII (Bosson, 1964: 11), CHÖÖMEJ (Aksenov 1973: 12), CHÖÖMIJ (Vietze 1969: 15-16), XÖÖMIJ (Hamayon 1973; Tran Quang Hai 1980: 162). Ricercatori francesi hanno altri termini per descrivere questa peculiare tecnica vocale come per esempio CHANT DIPHONIQUE o BIPHONIQUE (Leipp 1971), Tran Quang Hai 1974, Gilles Leothaud 1989, VOIX GUIMBARDE, VOIX DEDOUBLEE (Helffer 1973, Hamayon 1973), e CHANT DIPHONIQUE SOLO (Marcel-Dubois 1979). Altri termini esistono in Inglese come SPLIT-TONE SINGING, THROAT SINGING, OVERTONE SINGING, e HARMONIC SINGING. In Germania è chiamato ZWEISTIMMIGEN SOLOGESANG. in Italia CANTO DIFONICO O CANTO DIPLOFONICO. Per convenienza, io ho impiegato il termine “OVERTONE SINGING[2]” per descrivere uno stile di canto eseguito da una singola persona che produce contemporaneamente una fondamentale che continua e un altro suono più acuto tra quelli della serie delle parziali o armoniche, che ricordano il suono del flauto . Come sono giunto al “Canto Armonico” (“overtone singing”) Nel 1970, al Department of Ethnomusicology (Musee de l’Homme), il Prof. Roberte Hamayon mi fece ascoltare le sue registrazioni fatte in Mongolia nel 1967 e nel 1969. Fui sorpreso dalla natura straordinaria e unica di questa tecnica vocale. Per molti mesi compii ricerche bibliografiche negli articoli dove era trattato questo stile di canto nel tentativo di ottenere informazioni sulla pratica del Canto Armonico, ma ricevetti piccole soddisfazioni. Spiegazioni meramente teoretiche e alcune volte di natura ambigua non fecero nulla di meglio che creare e incrementare la confusione col il che la mia ricerca fu abbandonata. A dispetto della mia completa ignoranza sul metodo impiegato per imparare il Canto Armonico praticato dai Mongoli, dai Tuvani e da altre popolazioni della Siberia, non mi scoraggiai minimamente per i risultati negativi ottenuti all’inizio dei miei studi dopo mesi di sforzo. Io lavorai interamente solo brancolando a mio modo nel buio per due lunghi anni, ascoltando frequentemente dalle registrazioni effettuate da Roberte Hamayon depositate nel Sound Archives del Department of Ethnomusicology del Musee de l’Homme. I miei sforzi non portavano risultati. Nonostante la conoscenza della tecnica dello scacciapensieri, il lavoro all’inizio fu difficile e scoraggiante. Provai anche a fischiare mentre emettevo un suono grave con la voce come fondamentale. Comunque all’analisi spettrografica si vedeva che non era simile alla tecnica Xöömij dei Mongoli. Alla fine del 1972 mi resi conto che ero ancora molto lontano dalla mia meta. Poi, un giorno, nel novembre del 1973, mentre cercavo di calmare i miei nervi nella terrificante congestione del traffico di Parigi, accadde che feci vibrare le mie corde vocali nella faringe con la bocca mezzo aperta recitando a memoria le lettere dell’alfabeto. Quando arrivai alla lettera “L”, e la punta della lingua stava quasi per toccare la cima del palato, sentii improvvisamente un suono armonico chiaro, puro e potente. Ripetei molte volte l’operazione ottenendo lo stesso risultato; tentai poi di cambiare la posizione della lingua sul palato mantenendo il suono di base. Una serie di palatali risuonò come un disturbo nelle mie orecchie. All’inizio trovai gli armonici dell’accordo perfetto. Lentamente, dopo una settimana di addestramento intensivo, slittando verso l’acuto o il grave con la fondamentale scoprii da me stesso il mistero del canto armonico, il cui stile appariva vicino a quello praticato dai Mongoli e dai Tuvani. IL MIO METODO DI ADDESTRAMENTO Dopo due mesi di “ricerca” e dopo numerosi esperimenti di vario genere, riuscii a creare una breve melodia di armonici. Questa è la mia “ricetta” per aiutare chiunque a fare questo primo passo per cantare gli armonici. 1. Intensificare la produzione vocale con una voce di gola 2. Pronunciare le lettere “I” e “U” collegandole insieme e ripetendo molte volte in un fiato. 3. Si faccia un suono nasale con la punta della lingua in posizione bassa. 4. In questo modo è possibile mettere a fuoco la linea degli armonici superiori sia in ordine ascendente che discendente. Questa è la prima tecnica, quella che io chiamo “tecnica a una cavità”. Ciò è piuttosto facile da fare e chiunque può ottenere due suoni simultanei nel giro di un minuto di pratica. La seconda “ricetta” aiuterà a produrre gli armonici chiari alla maniera dello stile Mongolo e Tuvano. Io chiamo questa “tecnica a due cavità”. 1. Si emetta il suono vocalico “E” più lungo possibile. 2. Si pronunci la lettera “L”. Mantenere la posizione con la punta della lingua che tocca il palato. In questa posizione la bocca è divisa in due cavità, una davanti e una dietro. 3. Si pronunci prima “LAANG” per diverse volte (primo esercizio) e poi “LOONG” per altrettante (secondo esercizio). Quando gli armonici sono udibili si canti tenendo la lingua contro il palato e contemporaneamente cambiando la forma della bocca come per pronunciare le vocali da “A” a “O” e successivamente da “O” a “A” eseguendolo molte volte in un fiato. 4. Si faccia un suono nasale. 5. In questa maniera si può produrre chiaramente la serie di armonici in stile Mongolo. Per i principianti gli armonici dell’accordo perfetto (Do, Mi, Sol, Do) sono facili da ottenere. Comunque, un allenamento particolarmente duro è necessario per ottenere scale pentatoniche. Ogni persona ha la sua altezza favorita che l’abilita a produrre una maggiore gamma di parziali. Questa fondamentale favorita varia secondo le qualita della voce del singolo cantante. NUOVI ESPERIMENTI DI CANTO ARMONICO Altri esperimenti dai quali ho appreso che è possibile ottenere due suoni simultaneamente in tre diversi modi: 1. nel primo modo la lingua è abbassata o leggermente curva, senza mai toccare in alcun modo il palato, e solo le labbra muovono il cavo orale. Con questa modalità del cavo orale, questa volta diviso in un’unica cavità, è possibile udire le parziali ma deboli e gli armonici più acuti non superano i 1200Hz. 2. La tecnica di base del secondo metodo è descritta sopra. Comunque, invece di tenere la bocca mezzo aperta è tenuta quasi chiusa con le labbra tirate indietro e molto strette. Perché le parziali siano molto chiare, la posizione delle labbra deve variare allo stesso tempo della lingua. Quando le parziali sono molto chiare e distinte allora la tecnica è esaurita. Gli armonici acuti possono arrivare alla zona dei 2600 Hz. 3. Nel terzo metodo la lingua è abbassata, e i denti stringono la lingua mentre si cantano le vocali “U” e “I”, con la contrazione dell’addome e dei muscoli della gola. Gli armonici più acuti possono giungere a 4200Hz. Altri nuovi esperimenti che ho iniziato a mostrare è che io posso mantenere l’armonico allo stesso livello di frequenza usato come “nota tenuta” e cambiare la linea delle fondamentali (per esempio Do, Fa, Sol, Do). Sono anche riuscito a creare una linea di fondamentali e una di armonici che muovono contemporaneamente in direzioni opposte. In altre parole io produco una linea fondamentale ascendente e, allo stesso tempo, una linea discendente di armonici. L’effetto armonico è piuttosto inusuale ed eccezionale. Nel 1989 io e il dottor Hugo Zemp abbiamo realizzato un film intitolato “THE SONG OF HARMONICS” che mostra una ripresa ai raggi X e una spettrografica, in tempo reale e con il suono sincronizzato, di brani di canto dei diversi paesi. Questo film prodotto dal CNRS –Audiovisivi e dalla French Society for Ethnomusicology, ottenne due premi (Grand Prize and Best Music Prize) al International Festival of Visual Anthropological Film in Estonia Ottobre 1990, un premio (Special Prize for Research) al International Festival of Scientific Film in Palaiseau (France) nel Novembre 1990, e il Grand Prize del International Festival of Scientific Film in Montreal (Canada) nel1991. Nella musica contemporanea occidentale gruppi di cantanti sono riusciti ad emettere due note contemporaneamente e sono stati creati brani di musica d’avanguardia e nell’ambito della musica elettoacustica. David Hykes con il suo Harmonic Choir, fondato a New York nel 1975, usa il canto armonico per collegarsi con l’universo cosmico nelle sue composizioni. Demetrio Stratos (1945-1979) ha usato il canto armonico per creare una relazione tra la voce e il subconscio. Nelle mie composizioni – improvvisazioni io raccomando sempre di investigare gli armonici per arricchire il mondo dei suoni. Altri esecutori di canto armonico sono i tedeschi Michael Vetter, Christian Bollmann, Michael Reimann, l’italiano Roberto Laneri, l’olandese Rollin Rachele, l’australiano Josephine Truman, i francesi Les Voix Diphoniques , Thomas Clements, Iegor Reznikoff, Tamia, tutti costoro hanno utilizzato il canto armonico nei loro lavori. Il canto armonico è praticato anche da numerosi gruppi (Oirat, Khakass, Gorno-Altai, Bashkir, Tuvin, Kalmuk) etnici al confine tra la Repubblica Russa e la Mongolia. In Rajasthan (India), in Taiwan presso il gruppo etnico Bunun, in Tibet presso i monaci dei monasteri Gyuto e Gyume, in Sud Africa presso la popolazione degli Xhosa, la pratica del canto armonico è nota e ovunque registrata. Io spero che dopo questa breve introduzione al mondo degli armonici, si possa avere un’idea riguardo l’esistenza del canto armonico in differenti aree del mondo e la possibilità di sapere come ottenere armonici vocali. Bibliografia AKSENOV, A.N. 1973: “Tuvin Folk Music”, Journal of the Society for Asian Music 4(2):7-18, New York. HAMAYON, R. 1980: “Mongol Music”, New Grove’s Dictionary of Music and Musicians 12: 482-485, Stanley Sadie (éd), MacMillan Publishers,Londres. LANERI, R. 1983: “Vocal Techniques of Overtone Production”,NPCA Quarterly Journal 12(2-3): 26-30. LEIPP, E. 1971: “Considération acoustique sur le chant diphonique”, Bulletin du Groupe d’Acoustique Musicale 58: 1-10, Paris.. LEOTHAUD, G. 1989: “Considérations acoustiques et musicales sur le chant diphonique”, Le chant diphonique, dossier n° 1: 17-43, Institut de la Voix, Limoges. TRAN QUANG HAI & GUILOU, D. 1980: “Original Research and Acoustical Analysis in Connection with the Xöömij Style of Biphonic Singing”, Musical Voices of Asia : 162-173, The Japan Foundation (éd), Heibonsha Ltd, Tokyo. TRAN QUANG HAI & ZEMP,Hugo. 1991: “Recherches expérimentales sur le chant diphonique”, Cahiers de Musiques traditionnelles : VOIX vol.4: 27-68, Ateliers d’ethnomusicologie /AIMP, Genève. TRAN QUANG HAI, 1975: “Technique de la voix chantée mongole: xöömij”, Bulletin du CEMO (14 & 15): 32-36, Paris. TRAN QUANG HAI, 1983: “Note à propos du chant diphonique mongol”, Catalogue de l’exposition Mongolie-Mongolie, Musée de l’Homme (éd), Paris. TRAN QUANG HAI, 1989: “Réalisation du chant diphonique”, dossier n°1 Le Chant diphonique : 15-16, Institut de la Voix, Limoges. TRAN QUANG HAI, 1990: “Les Musiques vocales”, L’Esprit des Voix, C.Alès (éd), La Pensée Sauvage: 43-52, Grenoble. TRAN QUANG HAI, 1991: “New Experimental About the Overtone Singing Style”, (Nouvelles Expérimentations sur le chant diphonique), Nouvelles Voies de la Voix, 1ère partie, Bulletin d’adiophonologie 7(5&6): 607-618, Besançon. TRAN QUANG HAI, 1995: ” Le chant diphonique: de……ion, historique, styles, aspect acoustique et spectral”, EM, ANnuario degli Archivi di Etnomusicologia dell’Accademia Nazionale di Santa Cecilia, 2:123-150, Rome. TRAN QUANG HAI, 1995: “Survey of overtone singing style”, EVTA (European Voice Teachers Association, Dokumentation 1994 (actes du congrès): 49-62, Detmold [1] Nome inglese dello scacciapensieri o maranzano. [2] In Italiano utilizzeremo “Canto Armonico”.